Nesse artigo irei mostrar como otimizar um Kafka Consumer
Apr 11, 2022
Recentemente escrevi um artigo que fala do funcionamento básico de um Kafka Consumer onde falei sobre rebalance, consumer group, loop poll e offsets.
Nesse artigo vou falar sobre alguns parâmetros básicos, mandatório e avançados para otimizarmos o Kafka Consumer, evitando rebalances constantes, lentidões e má performance.
Já sabemos que o primeiro passo para otimizar o Kafka Consumer é escalar o consumer até o numero máximo de partições, assim vai atingir um maior throughput, sem alterar nenhum parâmetro.
Configurações obrigatórias do Kafka Consumer
Há alguns parâmetros que são essenciais, e mandatório, para o funcionamento de um consumer:
-
bootstrap.server: é o endereço do Kafka Cluster. Aqui pode ser usado o host e porta de todos os brokers ou de alguns especificamente. O recomendado é utilizar um loadbalance;
-
key.deserializer: qual classe será utilizada para realizar a deserialização da key;
-
value.deserializer: qual a classe será utilizada para realizar a deserialização do value;
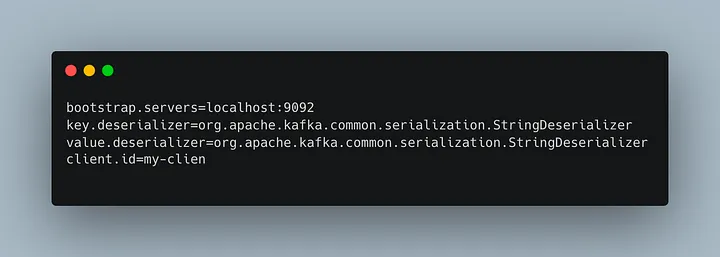
As mensagens que repousam no storage do kafka são tratadas como binários pelos brokers e quem realiza a serialização e deserialização, são as pontas, ou seja, producers e consumer.
Principais propriedades
Acima vimos as propriedades mandatórias, que sem elas nada funciona. Porém, há numeras propriedades que é possível ajustar para deixar o consumer mais adequado para sua app. Não vamos falar sobre todas aqui, vamos focar somente nas mais importantes. Caso queira ver todas as configs e a descrição detalhadas de cada uma delas, basta ir na doc official do Kafka.
-
group.id: Valor que identifica qual consumidor pertence tal instância;
-
fetch.max.wait.ms: O máximo de tempo, em milissegundo, que o consumer ficará bloqueado esperando para buscar eventos no broker, se não tiver o mínimo de dados declarado no parâmetro abaixo. O valor default é 500 milissegundos;
-
fetch.min.bytes: A quantidade mínima de dados em bytes que deverá retornar para cada busca por dados. Se não tiver dados suficiente que atinja a quantidade determinada aqui, o consumer irá esperar o tempo declarado no parâmetro acima antes de responder a requisição por dados. O valor default é 1 byte;
-
enable.auto.commit: Se estiver true, que é o valor default, o offset será commitado em background em um intervalo de tempo, especificado pelo parâmetro abaixo;
-
auto.commit.interval.ms: A frequência, em milissegundo, que o consumer irá realizar o commit do offset em backgroud, isso se o parâmetro acima estiver como true. O valor default é 5000 (5 segundos);
-
session.timeout.ms: Tempo em milissegundos que determina a espera máxima para detecção de falha de um consumer. O consumer envia periodicamente heartbeats par indicar para o broker que está ativo. Se nenhum heartbeat for recebido pelo broker antes do tempo de expiração deste parâmetro, o broker coordinator irá remover o consumer do grupo de consumidores, iniciando um rebalance. O valor default é 10000 (10 segundos);
-
heartbeat.interval.ms: Tempo determinado para envio de heartbeat para o broker. O valor default é 3000 (3 segundos), ou seja, a cada 3 segundos o consumer envia heartbeat para o broker;
-
auto.offset.reset: Determina qual será o ponto inicial do consumo dos dados caso seja a primeira vez que esteja subindo o consumer, ou não executa há um tempo. Os valores possíveis são: earliest — que inicia o consumo dos eventos desde o inicio, consumindo todas as mensagens que estiverem retidas no kafka; latest — inicia o consumo do último evento publicado desde a inicialização da aplicação; none — lança uma exceção se não tiver offset já registrado para o consumidor que está subindo;
-
max.poll.interval.ms: O máximo de espera entre invocações do poll() para busca de mais dados. Se o poll() não for chamado dentro desse intervalo de tempo o consumer será considerado em falha e isso irá iniciar um novo rebalance, removendo esse consumer. O valor default é 300000 (5 minutos);
-
max.poll.records: O numero máximo de eventos retornado em uma simples chamada de poll(). O valor default é 500.
Com o ajuste adequado dessas propriedades nós conseguimos atingir alguns pontos:
-
Escalabilidade do consumidor para aumentar o throughput;
-
Otimização de latência que leva para que as mensagens sejam buscadas no broker;
-
Minimizar perdas ou duplicidade de dados;
-
Minimizar impactos de rebalances constantes para reduzir downtime;
-
Reduzir o atraso (Lag)de mensagens não processadas.
Melhorando throughput
Para melhorar o throughput do consumer e, consequentemente, reduzir a quantidade de request no broker Kafka basta ajustar 2 propriedades, o fetch.max.wait.ms e fetch.min.bytes.
Quando uma aplicação consumer realiza a chamada de poll() por mais dados, essas propriedades governam o tando de dados (em bytes) que são capturados dentro do request.
Se você aumentar o fetch.min.bytes, por exemplo, com um valor maior que o padrão o consumer vai realizar menos requests para o broker e irá trazer mais dados em um único batch, consequentemente irá reduzir a sobrecarga de CPU no consumer e no broker.
Com esse pequeno ajuste o consumer poderá aumentar consideravelmente o throughput, mas pode inserir um pequeno aumento de latência, pois ele vai esperar mais tempo para atingir o valor de dados definido.
Você pode utilizar uma dessas propriedades abaixo. Ajustando as duas com o valor que se adequar melhor ao cenário da sua aplicação:
# ...
fetch.max.wait.ms=500 # Valor default (tempo de espera)
fetch.min.bytes=16385 # O valor default aqui é 1 byte
# ...Minimizando perda ou duplicidade de dados
Para aplicações que requer durabilidade das mensagens, é possível aumentar o nível de controle sobre os consumers quando commitam offsets para minimizar o risco de perda ou duplicidade de dados.
O mecanismo de auto-commit do Kafka consumer pode ser bastante conveniente para maioria dos casos. Quando habilitado essa propriedade do consumer basicamente ‘commita’ as mensagens automaticamente cada período de tempo determinado pelo auto.commit.interval.ms. No entanto essa conveniência tem o seu preço, com essa forma de commit habilitada há grande chance de perdas e/ou duplicidade de dados:
-
Perda de dados: se sua aplicação commita um offset e antes de realizar o processamento daquele batch de mensagem falha, essas mensagens não serão reprocessadas depois de restartar a aplicação consumidora;
-
Duplicidade de dados: Se sua aplicação processou todas as mensagens do batch e falha antes de realizar o commit automático, quando sua aplicação for reinicializada ela vai reprocessar esse conjunto de mensagem que não foi commitado, mas já foi processado.
A primeira coisa que você pode fazer para minimizar esse risco é diminuir o intervalo de commit auto.commit.interval.ms.
# ...
auto.commit.interval.ms=1000
# ...Mas isso não elimina 100% de chance de perca ou duplicidade de dados. Uma outra alternativa (e que acho melhor) é desativar o commit automático pelo parâmetro enable.auto.commit, colocando para false, e realizando o commit de maneira ‘manual’ e cadenciada após cada processamento de lote de mensagem.
# ...
enable.auto.commit=false
# ...Desativando o commit automático, você deve controlar quando sua aplicação vai realizar o commit dos offsets. Para fazer isso você pode introduzir as chamadas do método commitSync e commitAsync no qual realiza o commit de offset especifico do tópico e partição do Kafka.
-
O commitSync realiza o commit de todos os offsets de todas as mensagens retornadas no poll(). No geral, uma nova chamada de poll() só é realizada quando todas as últimas mensagens forem processadas. Essa abordagem pode afetar o throughput e latência, deixando o consumer mais lento, mas com um risco bem menor de perca ou duplicidade de mensagem;
-
O commitAsync, diferente do anterior, não espera o coordinator broker responder pelo commit request. Essa abordagem tem uma latência e throughput melhor que o commitSync, mas há um risco de duplicar dados quando houver um rebalance.
Em resumo, se você procurar uma menor latência e dados duplicados não é um problema para sua aplicação, a melhor escolha é o commitAsync. Porém, se está preocupado com a duplicidade e não liga muito para latência a melhor escolha é o commitSync.
Minimizando rebalances e downtimes
Sabemos que o consumer dentro de um grupo fica enviando constantemente heartbeat para o cluster do Kafka para avisar que está funcional.
Por padrão o tempo de envio de heartbeat e timeout são bem agressivos no Kafka Client, pois quanto mais rápido identificar uma falha, melhor.
Mas esse tempo pode não está condizente com a realidade da sua aplicação, por isso entender bem como funciona esses parâmetros é essencial para minimizar rebalances constantes e downtimes desnecessários.
Basicamente você pode utilizar 2 parâmetros para ajustar o tempo de envio de heartbeat e o timeout deste.
-
heartbeat.interval.ms especifica o intervalo em milissegundos de envio de heartbeats do consumer group para o coordinator indicando que o consumer está ativo, conectado e funcional. O intervalo do heartbeat deve ser menor que 1/3 do timeout. Aumentar esse parâmetro pode livrar sua aplicação de realizar rebalances constantes, mas por outro lado pode fazer com que sua aplicação demore para detectar uma possível falha.
-
session.timeout.ms especifica o máximo de tempo em milissegundos que um consumer dentro de um consumer group pode ficar sem enviar heartbeat antes de ser considerado inativo e provocar um rebalance. Aumentar esse parâmetro pode reduzir rebalances constantes, mas por outro lado pode fazer com que o coordinator do Kafka demore para detectar uma possível falha de um consumer.
# ...
heartbeat.interval.ms=3000 \#valor default (3 segundos)
session.timeout.ms=10000 \#valor default (10 segundos)
# ...
Monitoração do heartbeat
Outro grande fator que provoca rebalances constantes é um backend lento. No Cliente Kafka há um controle muito grande de detecção de falha que pode ajudar muito como também pode gerar muitos problemas em casos de má configuração.
Um dos principais pontos de rebalances constantes é por conta de backend lento, mas isso não quer dizer que se você tem um backend lento não pode usar o Kafka (não é uma verdade absoluta), mas precisará ajustar as configurações para adequar sua aplicação ao funcionamento normal da mesma.
Quando um rebalance é provocado nos logs da aplicação consumidora é informado a causa, por isso é muito importante está com os logs estruturados para entender a causa do rebalance.
Abaixo um exemplo de log de uma aplicação que sofreu rebalance por causa do tempo de expiração do poll.
2022–04–09 20:28:02.213 WARN 31942 — — [p-kafka-lab-two] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=kafka-lab-0, groupId=group-kafka-lab-two]consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.2022–04–09 20:28:02.213 INFO 31942 — — [p-kafka-lab-two] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=kafka-lab-0, groupId=group-kafka-lab-two]Member kafka-lab-0–399a1c02–404f-4d17-a6b9-a27833523ca1 sending LeaveGroup request to coordinator164.90.255.111:9094 (id: 2147483645 rack: null) due to consumer poll timeout has expired.É possível ajustar o tempo de processamento que a aplicação vai aguardar entras as chamadas subsequente de poll() e a quantidade máxima de dados ajustando dois parâmetros:
-
max.poll.interval.ms determina o intervalo limite que o consumer irá ficar processando as mensagens do último poll(). Se o consumer não realizar uma outra chamada dentro desse tempo, o coordinator vai considerar o consumer em falha e vai provocar um rebalance. Se sua aplicação demora muito tempo para processar os eventos você pode aumentar esse parâmetro para esperar mais tempo e conseguir processar os eventos no tempo adequado. Só tenha em mente que se aumentar muito esse valor pode fazer com que o coordinator demore mais para descobrir que sua aplicação falhou.
-
max.poll.records determina a quantidade máxima de eventos retornado em cada poll(). Se sua aplicação demora muito para processar cada evento, você pode reduzir o valor desse parâmetro para que não atinga o tempo limite do parâmetro anterior. O importante saber é que reduzir muito esse parâmetro pode ser um grande ofensor para o cluster Kafka, uma vez que vai ser necessário realizar muitas chamadas de fetch request, sobrecarregando tanto o consumer quando os brokers, adicionando carga de CPU desnecessária.
# ...
max.poll.interval.ms=300000 \#valor default (5 minutos)
max.poll.records=500 # valor default
# ...
métrica de chamadas subsequentes do poll.

métrica da última chamada de poll
Conclusão
O Kafka Cliente permite muitos ajustes que vão além desses abordados nesse artigo. O mais importante aqui é saber que é possível ajustar o consumer para a necessidade especifica da sua aplicação, tirando o melhor que o Apache Kafka pode proporcionar.
É valido saber que se tem uma aplicação consumidora que é lenta por natureza — que tem o tempo de processamento alto com cada evento — obviamente essa aplicação vai ter um LAG (atraso na leitura de eventos), pois a característica do producer é ser mais rápido que o consumer.
As configurações e sugestões mostradas aqui podem ajudar a sua aplicação reduzir esse LAG e ter uma performance um pouco melhor do que usando as configurações padrões. Não há uma receita especifica para cada tipo de aplicação, é importante realizar testes de carga e performance na aplicação e ir ajustando tais parâmetros de acordo com os resultados obtidos.
Outro ponto extremamente importante, é ativar a monitoração no cliente kafka, assim você vai ter visão especifica e mais detalhada de como está a performance do seu consumer e realizar ajustes mais precisos com evidência dos resultados, sem falar que em um momento de troubleshooting vai ajudar muito.
Em um próximo artigo irei trazer como instrumentar monitoração em aplicações consumer Java com Spring Boot.
Referências
Optimizing Kafka consumersWe recently gave a few pointers on how you can fine-tune Kafka producers to improve message publication to Kafka. Here…
strimzi.io
Apache KafkaHere is a description of a few of the popular use cases for Apache Kafka®. For an overview of a number of these areas…
kafka.apache.org