
Context Engineering: como transformar agentes de IA em desenvolvedores confiáveis
Guia completo do Estágio 1 ao Estágio 3 para transformar uso de agentes de IA em um sistema previsível, com contexto estruturado, skills e memória de projeto.Uberlândia, Minas Gerais, Brasil, América do Sul, Planeta Terra. Março de 2026.
Se você está lendo esse post no futuro longínquo (a partir de Abril de 2026), é bem provável que você venha a rir desse conteúdo. Mas eu preciso pôr isso por escrito. Preciso organizar o que sei, até o momento, antes que invalidem de novo.
A IA é uma realidade. Não é mais um elemento da ficção científica, mas sim um colega de trabalho chato que fica dando pitaco em tudo que escrevo.
Agora temos IA em tudo que é canto. Tem IA no editor, IA no navegador, IA no sistema operacional, no carro, na geladeira, até mesmo na sua privada (não, não estou brincando).
No meio desse turbilhão estamos nós, desenvolvedores, contentes porque finalmente aprendemos a usar os agentes — essas entidades cuja função é sugar dinheiro e cuspir código fonte — e fingindo que não tem c-level tentando nos obliterar da realidade.
Depois de quase um ano de esforço árduo, de muito café com monster de mango loco e de ter apostado uma quantidade indecente de tokens — suficiente para o Tigrinho sentir ciúme — eu finalmente estava com meus agentes devidamente configurados!
Mas, como a vida não é um morango, agora chega um coachador (minha tradução de coach) metido a Neo do Linketrix, com conteúdo sensacionalista, te falando que você deve instalar uma tal de skills, tal qual no filme, e matar os Agentes Smith!
Sério? Nem bem terminamos de aprender a usar os agentes, e já querem que a gente mude tudo de novo?
Mas chega de mimimi. Vamos ao que interessa.
Índice
- Índice
- Introdução
- 1. A Virada de 2026: De Prompt Engineering para Context Engineering
- 2. O Que É Context Engineering
- 3. Os 3 Estágios de Maturidade
- 4. Ferramentas e Seus Arquivos de Contexto
- 5. Como Criar um CLAUDE.md e AGENTS.md que Funcionam
- 6. Como Criar Skills que Realmente Funcionam
- 7. Memória Estruturada: O Agente que Lembra
- 8. Multi-Agente na Prática
- 9. O Skill Graph: Estágio 3 na Prática
- 10. Guia Passo a Passo: Da Fase 0 à Fase 3
- 11. Armadilhas e Anti-Padrões
- 12. Conclusão e Próximos Passos
- Apêndice: Templates Completos
Introdução
Não vou nem perguntar, eu vou afirmar: Se você tem usado a IA no seu dia a dia:
- você já passou horas ajustando a forma como pede algo para um agente de IA, só para descobrir que na próxima sessão ele esqueceu tudo.
- você já viu o agente gerar código perfeito do ponto de vista técnico, mas completamente fora dos padrões do seu projeto.
- você já precisou corrigir uma violação arquitetural que deveria ser impossível — e o agente não percebeu.
- você já teve vontade de apertar o shift + delete ou executar um
rm -rfna raiz do servidor da OpenAI só para evitar que o agente parasse de beber tokens feito um Opala desregulado dando voltas no quarteirão. - você ou toma remédios controlados, ou está tentando parar, ou está torcendo pra começar.
A boa notícia é que tudo isso tem causa em comum, e ela não é o modelo, nem é a qualidade do LLM que você escolheu.
O problema é o contexto que você oferece.
Durante anos, o foco esteve no prompt: como perguntar melhor, como ser mais específico, como dar exemplos no chat.
"Vamos fazer engenharia de prompt, amiguinho!" eles disseram. E tal qual um jogo de gacha, tal qual um loot box de jogo mobile, você apostava tokens, testava variações, e às vezes conseguia o resultado que queria.
Isso funcionou por um tempo. Mas os agentes se tornaram parte permanente do fluxo — não mais uma curiosidade, mas uma ferramenta usada em toda PR. E ficou claro: prompt engineering não escala.
Um agente sem estrutura de contexto é como aquele seu amigo desenvolvedor júnior, que muda de emprego toda semana, e entra sem onboarding, sem documentação, sem acesso às decisões que o time já tomou. A cada sessão ele começa do zero e repete os mesmos erros.
Context engineering é a disciplina que resolve isso.
Não é sobre o que você pede. É sobre o ambiente que você cria para que o agente trabalhe.
É, Coachador. Agora, nós temos que saber como criar esse ambiente. E, assim como ocorre no nosso ambiente, se o ambiente do agente for tóxico, ele vai produzir resultados intoxicados. Tal qual um ser humano, um agente alcoolizado não vai dirigir em linha reta.
Este artigo cobre o caminho completo: do desenvolvedor que usa IA no chat (Estágio 1) até o projeto com um grafo de capacidades executáveis onde violações arquiteturais são estruturalmente impossíveis (Estágio 3). Os exemplos usam Node.js + Express + React, mas os princípios se aplicam a qualquer stack.
1. A Virada de 2026: De Prompt Engineering para Context Engineering
A Linha do Tempo
Para entender onde estamos, é útil ver como chegamos até aqui:
-
2023 — A era do prompt engineering. A habilidade mais valorizada era ser que nem um pretendente esforçado e saber formular o pedido perfeito. Você balançava um galho de árvore e caíam pelo menos uns 5 vendedores de cursos de "prompt engineering". O foco estava em o que pedir ao modelo.
-
2024 — A era dos agent frameworks. LangChain, AutoGen, CrewAI. A ideia era orquestrar múltiplos agentes em pipelines complexos. Era fazer com a IA a mesma bagunça que seu patrão faz na empresa. Multi-agente virou a buzzword do ano. Tinha c-level se molhando todo ao cogitar demitir a equipe inteira.
-
2025 — O recuo do multi-agente. As arquiteturas complexas de agentes múltiplos mostraram problemas sérios: perda de contexto entre agentes, overhead de comunicação, dificuldade de debug. A lei de Conway é implacável e a estrutura agêntica replicava os mesmos problemas da estrutura humana. A indústria começou a preferir um único agente bem configurado.
-
2026 — Context engineering. O campo inteiro mudou de foco. A pergunta deixou de ser "como eu peço?" e passou a ser "o que o agente vê antes de responder?". E assim nascem as skills.
A Mudança de Paradigma
| Dimensão | Prompt Engineering | Context Engineering |
|---|---|---|
| Foco | O pedido (o que perguntar) | O ambiente (o que o agente vê) |
| Unidade de trabalho | O chat | O repositório |
| Escala | Não escala (cada sessão é única) | Escala (contexto persiste) |
| Resultado | Imprevisível entre sessões | Consistente e estruturado |
| Quem define | O dev, no momento do pedido | O time, antecipadamente |
| Analogia | Dar instruções verbais toda vez | Escrever o manual de operações |
Os Números que Mudaram Tudo
Dois estudos publicados no início de 2026 reformularam como a indústria pensa sobre contexto:
SkillsBench (fevereiro/2026): Projetos com skills bem curadas (unidades de conhecimento procedural carregadas sob demanda) apresentaram +16,2 pontos percentuais de taxa de sucesso em relação a projetos sem skills. Mais surpreendente: modelos menores com skills bem construídas performaram comparável a modelos maiores sem skills.
Evaluating AGENTS.md (fevereiro/2026): Contexto excessivo degrada o raciocínio do modelo progressivamente. Arquivos de contexto com mais de 200 linhas reduziram a taxa de sucesso em mais de 20%. Em alguns experimentos, projetos sem contexto global performaram melhor do que projetos com documentação extensa — porque o agente explorava menos e tomava decisões mais focadas.
A conclusão prática: mais contexto não é melhor contexto. A arte está em curar o mínimo necessário.
Operação de Janela de Contexto (na prática)
No dia a dia de CLIs de coding, a sessão nunca começa do zero. Antes do primeiro prompt, a ferramenta já carregou instruções de sistema, definições de ferramentas e arquivos de contexto do projeto (CLAUDE.md, AGENTS.md, etc.).
Na prática, uma heurística útil é trabalhar na faixa de 40% a 60% de utilização de contexto. Não é regra rígida, mas acima dessa faixa tende a aumentar perda de detalhe, recuperação confusa de informação e microalucinações.
No Claude Code, isso pode ser monitorado com /context e controlado com /compact. Para não compactar tarde demais, você pode antecipar o limite de auto-compactação, no arquivo de configuração do Claude Code:
{
"env": {
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "50"
}
}
Se 50 ficar agressivo para o seu fluxo, ajuste para 60 ou 70 e monitore qualidade x custo. E um cuidado importante: compactar sem instrução explícita pode resumir demais; ao usar compactação, peça para preservar decisões, restrições e pendências.
Outro fator que consome janela de contexto é a quantidade de skills habilitadas simultaneamente. Segundo o guia oficial da Anthropic, ter mais de 20 a 50 skills ativas ao mesmo tempo causa degradação perceptível — o modelo fica mais lento e as respostas perdem qualidade. Se o projeto crescer a ponto de ter dezenas de skills, considere habilitação seletiva (ativar apenas as skills relevantes para a tarefa) ou "skill packs" — grupos de skills ativados por contexto.
A Frase que Resume Tudo (Com Um Asterisco Importante)
"Você está ensinando o agente. Portanto, também deveria estar restringindo."
Essa frase captura um insight real, mas que muita gente não presta atenção. O formato ideal de instrução depende de onde ela vai parar. E quando você pesquisa a documentação oficial dos vendors, descobre que cada um deles já mapeou isso:
Nível 1: Arquivo de configuração global (CLAUDE.md, AGENTS.md, copilot-instructions.md)
Aqui, imperativo seco é o que funciona. A documentação do Claude Code é direta: "Para cada linha, pergunte: remover isso faria o Claude errar? Se não, corte." Cada token consumido nesse slot é token que falta durante toda a sessão. Então:
ALWAYS extend BaseEntity for domain models.
Funciona. Não precisa de justificativa. É uma regra simples, sem ambiguidade, num espaço caro. Isso vale para todos os modelos — Claude, Copilot, Gemini. Aqui, brevidade é universal.
Nível 2: Skills e instruções especializadas (SKILL.md, .instructions.md)
Aqui a coisa muda. O guia oficial de Skills da Anthropic usa um padrão que mistura imperativo com uma frase curta de consequência:
## Critical
NEVER commit directly to main.
Why: CI pipeline runs destructive migration tests on main — a direct push can wipe staging data.
Essa frase extra não é "dar satisfação" ao agente. É dar ao modelo informação suficiente para generalizar — para aplicar a regra mesmo em cenários que você não previu explicitamente. Skills têm mais espaço (são carregadas sob demanda), então o custo de token é menor e o ganho de aderência compensa.
A OpenAI segue lógica semelhante no guia de GPT-5.4: blocos XML com diretivas claras frequentemente acompanham uma frase de contexto situacional ("This is especially important for workflows where...").
Nível 3: Prompts diretos
Aqui, contexto e motivação ajudam de verdade. A própria Anthropic recomenda explicitamente:
"Providing context or motivation behind your instructions can help Claude better understand your goals and deliver more targeted responses. Claude is smart enough to generalize from the explanation."
Tradução: "Fornecer contexto ou motivação por trás de suas instruções pode ajudar o Claude a entender melhor seus objetivos e fornecer respostas mais direcionadas. O Claude é inteligente o suficiente para generalizar a partir da explicação."
Então aquela frase que parecia "ensinar demais" no AGENT.md — "Use BaseEntity porque ela oferece serialização automática, integração com o ORM e facilita testes" — vai ser útil num prompt. O modelo usa o porquê para inferir quando a regra se aplica e quando não se aplica.
Resumindo: quanto maior o nível em que você estiver atuando, menos explicação você precisa dar e mais imperativo pode ser. Quanto mais próximo do prompt, mais explicação e motivação ajudam o modelo a generalizar.
Onde os modelos divergem
Um detalhe que vale registrar: os modelos não reagem da mesma forma à ênfase.
-
Claude 4.5/4.6 ficou mais sensível a linguagem agressiva. A Anthropic agora recomenda trocar
CRITICAL: You MUST use this toolporUse this tool when...— porque CAPS e ênfase excessiva podem causar overtriggering: o modelo aplica a regra com mais rigidez do que você queria. Para Claude, firmeza > agressividade. -
Modelos de raciocínio da OpenAI (o3, o4-mini) funcionam como um colega sênior: você dá a meta e confia que ele resolve os detalhes. Já modelos GPT (4.1, 5.4) ainda se beneficiam de instruções explícitas e estruturadas, como um colega júnior que performa melhor com orientação clara.
-
Gemini enfatiza "be precise and direct" e "prioritize critical instructions", mas sem posição explícita sobre explicar o porquê. Na prática, frameworks de raciocínio do Gemini frequentemente incluem contexto de restrições com rationale.
Onde todos concordam
Documentação narrativa (parágrafos longos explicando decisões arquiteturais) não é instrução. Agentes querem contexto executável — regras, restrições, exemplos, padrões. A diferença real não é "restringir vs. explicar", mas calibrar a densidade de explicação ao tipo de contexto e ao custo de token naquele slot.
| Slot | Formato | Token budget | Regra |
|---|---|---|---|
| CLAUDE.md / AGENTS.md | Imperativo seco | Caro (sempre carregado) | Corte tudo que não previne erro |
| SKILL.md / .instructions.md | Imperativo + brief WHY | Moderado (sob demanda) | Adicione consequência quando a regra não é auto-evidente |
| Prompt direto | Contexto + motivação | Livre (descartável) | Explique o suficiente para o modelo generalizar |
2. O Que É Context Engineering
Definição
Context engineering é a arte e a disciplina de curar o que um agente de IA vê antes de responder, com o objetivo de produzir resultados consistentes, previsíveis e alinhados com as necessidades do projeto.
Não confunda com "context window", que é o limite técnico de tokens que um modelo pode processar. Context engineering é uma disciplina, não uma restrição. É sobre escolher o que colocar na janela de contexto, não sobre o tamanho dela.
Os 5 Tipos de Contexto
Todo agente que trabalha em um projeto de software precisa de cinco tipos de contexto distintos:
1. Contexto de Identidade
Quem é o projeto, qual é a stack, qual é a arquitetura. É a resposta às perguntas: "Onde estou?" e "Como este projeto funciona?"
Exemplos: nome do projeto, tecnologias usadas, estrutura de diretórios, padrão arquitetural (MVC, Clean Architecture, etc.).
2. Contexto de Restrições
O que NUNCA fazer. São as regras que protegem integridade arquitetural, segurança, padrões do time.
Exemplos: "NUNCA importe Express na camada de domínio", "SEMPRE escreva testes para novos Use Cases", "NUNCA acesse a API diretamente em componentes React".
3. Contexto Procedural
Como executar operações específicas, passo a passo. São os checklists e workflows que garantem que uma operação seja executada da forma correta.
Exemplos: como criar uma nova entidade de domínio, como adicionar um endpoint HTTP, como escrever um teste de integração.
4. Contexto de Estado
Decisões já tomadas, padrões confirmados, bugs conhecidos, estado de migrations. É a memória do projeto — o que aconteceu antes desta sessão.
Exemplos: "Em março/2026 decidimos usar Joi para validação no lugar de express-validator", "O módulo de pagamentos ainda está em legado, não migre ainda".
5. Contexto Temporário
O que está acontecendo agora: os arquivos abertos no editor, a seleção de código atual, a tarefa específica desta sessão. Este contexto é gerenciado automaticamente pelas ferramentas.
O Funil de Contexto
Pense no contexto como um funil que vai do mais amplo ao mais específico:
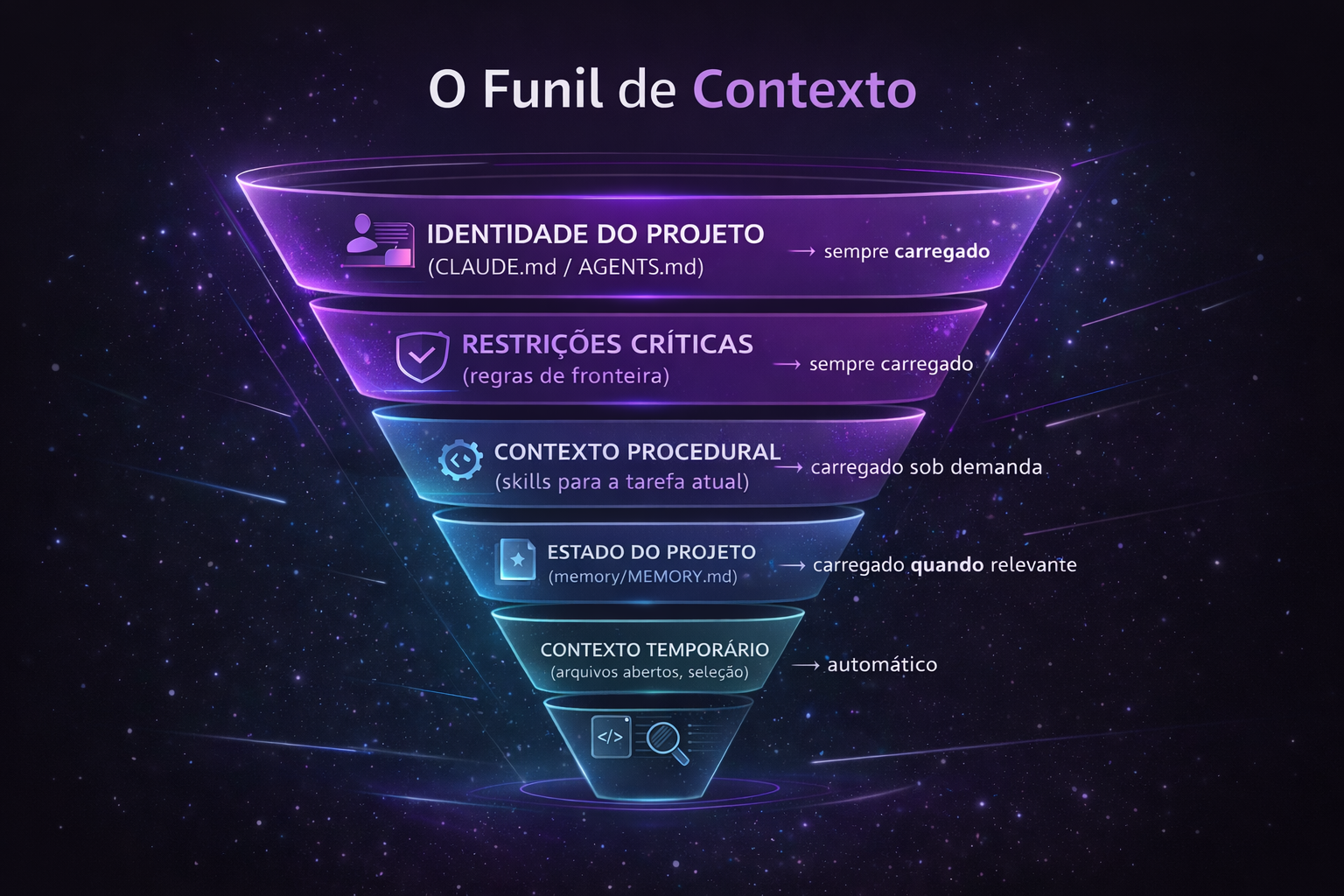
A chave é que cada camada é carregada no momento certo, não tudo de uma vez. Um agente que precisa criar uma entidade de domínio não precisa carregar o contexto de como escrever um teste de integração. Essa separação é o que permite que o sistema escale.
A Analogia do Dev Novo
Imagine contratar um desenvolvedor experiente para o seu projeto. No primeiro dia, você:
- Mostra a arquitetura do sistema (identidade)
- Explica o que é proibido: não commitar na main, não usar
var, não chamar API direto do componente (restrições) - Ensina os processos: como criar uma nova feature, como fazer deploy, como escrever testes (procedural)
- Apresenta o histórico: "usamos Redux, mas estamos migrando para Zustand, não crie nada novo em Redux" (estado)
No segundo dia, ele está trabalhando. Você não precisa repetir tudo isso.
Como diria o Chaves: "Isso e só um supositório!". Nós sabemos que o onboarding não costuma ser assim.
O que fazemos (e ainda consideramos boa prática) é chunchar (ênfase no termo técnico chunchar) no novo dev uma CHAPROCA DE DOCUMENTAÇÃO pra essa pessoa se virar sozinha — isso quando há documentação. Ela que lute com Arqueologia de Software pra entender o que existe. Ele que invoque seus poderes mediúnicos e use a Psicografia de Código pra adivinhar o que o autor quis dizer.
O resultado é que a pessoa será soterrada de informação, vai tiltar e passará semanas paralisada e confusa. Toda vez que ela for fazer algo, vai ter que consultar a documentação (que ela não conhece bem) ou perguntar para alguém. E, ainda assim, vai cometer erros, vai ter retrabalho, vai parar outras pessoas...
Um agente de IA, sem context engineering, é como um júnior contratado do zero, sem onboarding, toda sessão. Com context engineering, ele sabe onde parou e onde tem que começar.
Agora que você já sabe o diagnóstico, vamos ver os graus da doença.
3. Os 3 Estágios de Maturidade
A maioria dos projetos que usa agentes de IA pode ser classificada em um de três estágios. Identificar onde você está é o primeiro passo para melhorar.
A Tabela dos Estágios
| Dimensão | Estágio 1 | Estágio 2 | Estágio 3 |
|---|---|---|---|
| Nome | Context Enthusiast | Structured Skills | Skill Graph Architecture |
| Sintoma principal | "funciona às vezes" | "funciona se eu souber pedir" | "funciona de forma previsível" |
| Arquivo principal | README longo ou prompt no chat | AGENTS.md + algumas skills | CLAUDE.md + skill graph |
| Memória | Nenhuma (cada sessão do zero) | Informal (notas no chat) | Estruturada e commitada |
| Fronteiras arquiteturais | Violações frequentes | Violações ocasionais | Estruturalmente impossíveis |
| Custo por feature | Alto (muito contexto manual) | Médio (algumas automações) | Baixo (contexto cirúrgico) |
| Multi-agente | Desconexo (cada tool diferente) | Parcial (alguma sobreposição) | Unificado (fonte de verdade única) |
| Skills | Nenhuma ou genéricas | Algumas, mistura de tamanhos | Grafo de micro + meta + constraint |
Sintomas do Estágio 1
Você está no Estágio 1 se:
- O contexto do agente mora no README ou em um prompt que você colou no chat
- Toda nova sessão começa com você explicando o projeto do zero
- O agente gera código tecnicamente correto mas arquiteturalmente errado
- Você tem mais de um agente (Claude + Copilot, por exemplo), mas eles seguem regras diferentes
- Depois de cada correção importante você pensa "precisava anotar isso em algum lugar"
- Skills existem, mas são longas e educativas ("como funciona a arquitetura") e menos procedurais ("como criar um endpoint seguindo os padrões")
- A taxa de sucesso do agente depende muito de como você formula o pedido
O que acontece no Estágio 1: O agente é competente, mas trabalha no escuro. Ele infere o que pode do código existente e do que você diz no chat, mas não tem estrutura para ser consistente entre sessões. Tipo estagiário numa sala sem luz. Ele sabe andar, mas bate em tudo.
Sintomas do Estágio 2
Você está no Estágio 2 se:
- Existe um AGENTS.md com regras básicas do projeto
- Existem algumas skills, mas misturadas: algumas focadas, outras genéricas
- O agente segue as regras quando você as menciona explicitamente, mas as viola quando você não menciona
- A memória existe, mas fica nos arquivos do Claude Code locais (não commitados)
- Diferentes ferramentas (Claude e Copilot, por exemplo) têm regras ligeiramente diferentes
- Algumas operações têm skills, outras não têm
- O agente às vezes precisa ser corrigido sobre padrões que "deveriam estar claros"
O que acontece no Estágio 2: Há estrutura, mas incompleta. O agente funciona bem quando você sabe exatamente qual skill invocar. Fica inconsistente quando a tarefa não se encaixa claramente em nenhuma skill existente.
O que Caracteriza o Estágio 3
No Estágio 3:
- Skills se referenciam: meta-skills orquestram micro-skills automaticamente
- Existe uma constraint-skill que é verificada antes de finalizar qualquer mudança
- A memória é commitada no repositório e disponível para todos os agentes e colaboradores
- AGENTS.md é a fonte de verdade única — outros arquivos referenciam, não duplicam
- O agente não precisa de instrução explícita para seguir o workflow correto de uma feature
- Violações arquiteturais são detectadas pelo próprio agente, não na PR review
- O custo de tokens por feature é estável — não cresce com o tamanho do projeto
O que acontece no Estágio 3: O repositório se torna um grafo de capacidades executáveis. Cada tipo de operação tem um caminho claro. O agente segue o caminho, não inventa. É o sonho de todo tech lead: um dev que segue o processo sem reclamar.
O Erro Mais Comum
A maioria dos projetos acredita estar no Estágio 2 quando ainda está no Estágio 1 com mais arquivos.
A diferença entre Estágio 1 e Estágio 2 não é a quantidade de documentação. É a qualidade da estrutura: skills focadas vs. genéricas, regras calibradas por slot vs. narrativa uniforme, memória persistente vs. volátil.
O teste rápido: abra seu arquivo de contexto principal. Se ele parece um README explicando a arquitetura para um humano novo, é Estágio 1. Se ele parece um checklist executável onde cada regra tem o formato certo para o slot onde vive — imperativo seco no AGENTS.md, consequência breve nas skills, contexto rico nos prompts — você está caminhando para o Estágio 2.
4. Ferramentas e Seus Arquivos de Contexto
O Problema do Multi-Agente
Quando você usa Claude Code, GitHub Copilot, Google Gemini e OpenAI Codex no mesmo projeto, cada ferramenta lê arquivos diferentes. Isso cria um risco real: regras inconsistentes entre ferramentas.
Se Claude Code segue uma restrição arquitetural, mas o Copilot não tem acesso a ela, você terá metade das suas PRs com violações — geradas pela ferramenta que não "sabia" da regra.
Pra evitar esse problema, o primeiro passo é compreender como cada ferramenta lida com arquivos de contexto.
A Tabela de Compatibilidade
| Arquivo | Claude Code | GitHub Copilot | Cursor | OpenAI Codex | Gemini CLI |
|---|---|---|---|---|---|
CLAUDE.md | ✅ Primário | ❌ Ignora | ❌ Ignora | ❌ Ignora | ❌ Ignora |
AGENTS.md | ✅ Fallback | ⚠️ Parcial | ✅ Lê | ✅ Lê | ✅ Lê |
.github/copilot-instructions.md | ❌ Ignora | ✅ Primário | ❌ Ignora | ❌ Ignora | ❌ Ignora |
.github/skills/*/SKILL.md | ❌ Ignora | ✅ Nativo | ❌ Não suporta | ❌ Não suporta | ❌ Não suporta |
.claude/skills/*/SKILL.md | ✅ Nativo | ❌ Ignora | ❌ Não suporta | ❌ Não suporta | ❌ Não suporta |
.agents/skills/*/SKILL.md | ⚠️ Via symlink | ⚠️ Via symlink | ✅ Nativo | ✅ Nativo | ✅ Nativo |
.cursorrules / .cursor/rules/*.md | ❌ Ignora | ❌ Ignora | ✅ Primário | ❌ Ignora | ❌ Ignora |
GEMINI.md | ❌ Ignora | ❌ Ignora | ❌ Ignora | ❌ Ignora | ✅ Primário |
Nota: A compatibilidade evolui rapidamente. No momento em que ler esse artigo, verifique a documentação atualizada de cada ferramenta. É provável que mais ferramentas adotem o padrão de skills ou que haja mudanças na forma como elas lidam com arquivos de contexto, em direção a uma maior unificação.
A localização exata das skills para cada ferramenta pode variar com as versões. Consulte a documentação oficial antes de criar a estrutura de diretórios.
A Estratégia de Localização Neutra
Um padrão emergente resolve o problema de skills em múltiplas ferramentas: usar .agents/skills/ como diretório canônico e criar symlinks nos diretórios específicos de cada ferramenta.
Esse diretório já é lido nativamente por Cursor, OpenAI Codex e Gemini CLI. Para Claude Code e GitHub Copilot, criamos symlinks que apontam para a mesma fonte de verdade:
.agents/skills/ ← fonte de verdade (open standard — Codex, Gemini, Cursor)
.github/skills/ → ../.agents/skills/ (symlink — Copilot nativo)
.claude/skills/ → ../.agents/skills/ (symlink — Claude Code)
Vantagens:
- Uma única fonte de verdade para todas as ferramentas
- Adicionar uma skill em
.agents/skills/a torna disponível em todas as ferramentas automaticamente - Git rastreia symlinks — a estrutura é portável e compartilhável
O mesmo padrão se aplica a instructions e outros arquivos de contexto: centralizar em .agents/, usar symlinks nos
diretórios específicos.
Obs: Se você usa Windows, vai ter um trabalho a mais para lidar com links simbólicos. Sugiro que use o WSL ou uma solução de contêiner para manter a estrutura de arquivos consistente. Ou sofra. Você já usa Windows. Já está acostumado com sofrimento.
A Estratégia das Três Camadas
"O que? Camadas? Na IA? Lá vem esse povo do Java complicar o que era simples."
É jovem, lá vamos nós de novo: Camadas não são complicação, são organização. E organização é o que salva o dia quando o projeto cresce.
É só mais uma aplicação do bom e velho princípio da separação de preocupações (Separation of Concerns). Se você colocar tudo em um único arquivo, ele vai virar um monstro difícil de manter e vai degradar o contexto mais rápido. Não é curioso como um produto de nossa inteligência acaba por se comportar como nossa inteligência?
Então, jovem gafanhoto...Colocando em termos mais simples, nós dividimos o trabalho em camadas para não encher seu contexto com informação irrelevante precipitadamente.
Para manter consistência entre ferramentas e gerenciar melhor o contexto delas, use uma arquitetura de três camadas:
Camada 1 — Universal (AGENTS.md)
Regras que valem para todos os agentes. Esta é a fonte de verdade. Tudo o que está aqui é repetido implicitamente em todas as ferramentas.
AGENTS.md
├── Arquitetura do projeto (5-8 linhas)
├── Regras críticas (5-10 regras imperativas)
├── Lista de skills disponíveis
└── Fallback (o que fazer se um arquivo não existir)
Camada 2 — Específica por Ferramenta
Arquivos otimizados para cada ferramenta. Não duplicam as regras do AGENTS.md — referenciam.
CLAUDE.md → para Claude Code (comandos npm, referência às skills)
.github/copilot-instructions.md → para Copilot (lista de skills traduzida)
.cursorrules → para Cursor (regras no formato que o Cursor entende)
Camada 3 — Procedural (skills/)
Carregada sob demanda. GitHub Copilot lê .github/skills/ nativamente. Claude Code lê .claude/skills/ nativamente. Para Codex, Gemini e Cursor, use .agents/skills/ com symlink (ver estratégia acima).
O Princípio Anti-Duplicação
A regra mais importante do multi-agente:
Cada regra tem UM único lugar de verdade. Os outros arquivos referenciam, nunca duplicam.
Se a regra "NUNCA importe Express na camada de domínio" está no AGENTS.md, o CLAUDE.md não repete a regra — ele diz "Ver AGENTS.md para regras completas". O copilot-instructions.md faz o mesmo.
Quando você precisa atualizar a regra, atualiza em um único lugar. Sem risco de inconsistência.
O Problema do applyTo
GitHub Copilot suporta um mecanismo de frontmatter applyTo nos arquivos de instructions:
---
applyTo: "src/**/*.js"
---
# Regras para arquivos JavaScript
Isso faz com que o Copilot aplique as instruções apenas quando o arquivo editado corresponde ao padrão. É uma funcionalidade poderosa — mas é exclusiva do Copilot.
Claude Code não usa esse mecanismo nativamente. Se você colocar applyTo no CLAUDE.md, Claude ignorará o frontmatter.
Solução prática: Use applyTo apenas em arquivos dentro de .github/instructions/ (que o Copilot lê), nunca em CLAUDE.md ou AGENTS.md.
5. Como Criar um CLAUDE.md e AGENTS.md que Funcionam
O Princípio do Tamanho
Antes de escrever uma linha, internalize esta regra:
- AGENTS.md ideal: menos de 60 linhas
- CLAUDE.md ideal: menos de 80 linhas
- Arquivo com mais de 150 linhas: candidato a refatoração
Não é minimalismo por estética. É eficácia. Como mostrado pelos estudos de fevereiro de 2026, arquivos excessivamente longos degradam o raciocínio do agente. O modelo "se perde" em justificativas e exemplos quando deveria aplicar restrições.
O Que Pertence ao CLAUDE.md
O CLAUDE.md é o arquivo que Claude Code lê automaticamente no início de cada sessão. Ele deve conter:
- Uma linha de identidade — o que é o projeto, qual a stack
- Arquitetura em 3-5 linhas — onde fica o código novo, o legado, o compartilhado
- 5-8 regras críticas — apenas NEVER/ALWAYS, sem justificativas
- 4-6 comandos essenciais — os que o agente usará com mais frequência
- Referência às skills — não lista, apenas aponta para onde estão
- Referência à memória — onde estão as decisões arquiteturais
Template Comentado para CLAUDE.md (Node.js + Express)
Abaixo, segue um pequeno template, em português, para um projeto Node.js/Express que está migrando para Clean Architecture. Ele segue as regras de brevidade e estrutura que discutimos.
# MeuProjeto API
Node.js/Express, Clean Architecture (migração desde 2025).
## Arquitetura
- NOVO: `src/{módulo}/domain|application|infrastructure` — Clean Architecture
- LEGADO: `src/controllers/`, `src/models/` — MVC, apenas manutenção
- COMPARTILHADO: `src/@shared/` — classes base, tratamento de erros
## Regras Críticas
- NUNCA importe Express, Sequelize ou `src/models/*` em `domain/` ou `application/`
- SEMPRE estenda BaseEntity para novas entidades de domínio
- NUNCA adicione lógica de negócio em Controllers
- SEMPRE escreva testes unitários para novos Use Cases
## Comandos
- `npm run dev` — Iniciar em desenvolvimento
- `npm run test` — Todos os testes
- `npm run test:unit` — Apenas testes unitários
- `npm run lint` — ESLint
- `npm run openapi:validate` — Validar spec OpenAPI
## Skills
Ver AGENTS.md para lista completa de skills e guia de seleção.
## Memória
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
Por que esse tamanho funciona: cada seção responde uma pergunta que o agente teria. Arquitetura responde "onde está o quê". Regras respondem "o que nunca fazer". Comandos respondem "como executar". O resto está referenciado, não duplicado.
O Que NÃO Colocar no CLAUDE.md
❌ Explicações de por que a regra existe
# Errado:
- NUNCA importe Express em domain/ porque isso viola o princípio de inversão
de dependência e torna o código difícil de testar...
# Certo:
- NUNCA importe Express em domain/
❌ Exemplos de código
Os exemplos vão nas skills, não no arquivo de contexto global.
❌ Histórico de decisões
"Em janeiro de 2025 decidimos usar Joi porque..." — isso vai no memory/MEMORY.md.
❌ Instruções de onboarding para humanos
CLAUDE.md é para o agente. README e pasta docs/ são para humanos. Se quiser explicar em mais detalhes para humanos, faça isso no README ou em um arquivo de onboarding separado. Ou use a pasta docs/.
❌ Listas longas de skills
Uma referência ao AGENTS.md é suficiente.
Bloco opcional no CLAUDE.md: disciplina do agente principal
Uma prática que melhora consistência é declarar explicitamente o papel do agente principal como orquestrador e delegar execução para subagentes em contexto limpo.
## Context Engineering (Main Agent Discipline)
O agente principal é **orquestrador**, não executor.
**Papel do agente principal:** coordenar arquivos, abrir subagentes, consolidar resumos e comunicar status.
**O agente principal NUNCA:** explorar o codebase amplamente, implementar mudanças grandes sozinho, processar saídas longas de terminal sem filtragem.
### Protocolo de comunicação com subagentes
- Todo prompt termina com: "Retorne resumo estruturado com [campos exatos]"
- Nunca pedir "retorne tudo"
- Meta de 10-20 linhas acionáveis por retorno
- Encadear subagentes passando apenas campos relevantes entre etapas
Esse bloco é opcional, mas ajuda a proteger o contexto principal de inchaço em tarefas longas.
Template para AGENTS.md
No caso do AGENTS.md, o foco é listar as regras de forma clara e referenciar os arquivos de contexto específicos. Ele deve ser um guia rápido para o agente entender onde encontrar cada tipo de informação.
# AGENTS.md — MeuProjeto
## Fonte de verdade
1. `CLAUDE.md` (contexto geral para Claude Code)
2. `.github/copilot-instructions.md` (contexto para Copilot)
3. `.github/skills/*/SKILL.md` (procedimentos sob demanda)
4. `docs/` (requisitos, specs, decisões)
## Skills disponíveis
**Backend (micro-skills — operações atômicas):**
- `/create-entity` — Criar/modificar entidade de domínio
- `/create-usecase` — Criar Use Case + teste unitário
- `/add-endpoint` — Adicionar endpoint HTTP
- `/write-unit-test` — Escrever teste unitário
**Backend (meta-skills — features completas):**
- `/implement-backend-feature` — Feature completa (entity → usecase → endpoint → tests)
- `/backend-generate-layers` — Novo módulo do zero
**Backend (constraint):**
- `/enforce-boundary` — Verificar fronteiras Clean Architecture
## Regras operacionais
- Para código novo: Clean Architecture (`domain → application → infrastructure`)
- Para código legado (`src/controllers/`): apenas manutenção
- Para testes: seguir `.github/instructions/testing.instructions.md`
- Nunca duplique regras já presentes neste arquivo em outros arquivos de contexto
## Fallback
Se um arquivo referenciado não existir:
1. Reportar brevemente o bloqueio
2. Usar melhor alternativa com base nos arquivos disponíveis
3. Registrar as suposições feitas
A Regra de Ouro da Manutenção
Um CLAUDE.md ou AGENTS.md começa a deteriorar quando alguém adiciona uma exceção, depois outra, depois uma nota explicativa. Em seis meses, tem 300 linhas e ninguém sabe o que ainda é válido.
Adote a regra:
Se você vai adicionar uma linha, remova uma linha equivalente ou a mova para um arquivo mais específico (skill ou memory).
6. Como Criar Skills que Realmente Funcionam
O Que É Uma Skill
Se você chegou até aqui, já deve estar impaciente comigo. "Que caralhos são skills?" é a pergunta martelando na sua cabeça, certo?
Uma skill é uma unidade de conhecimento procedural carregada sob demanda. É a resposta à pergunta: "como executar esta operação específica neste projeto?"
Não confunda skill com documentação. Documentação explica para humanos. Skill instrui o agente.
A analogia mais precisa é um runbook de operações: um documento que um técnico abre quando precisa executar um procedimento específico. Ele não lê o runbook inteiro todo dia — só quando vai executar aquele procedimento.
Caso ainda não saiba, a skill é um arquivo markdown dividido em duas partes: frontmatter (nome + descrição) e corpo (checklist passo a passo).
O agente carrega o frontmatter (nome + descrição) de todas as skills disponíveis. É como ter, em mãos, fichas indicando quando usar cada skill. Quando a tarefa combina com uma skill, ele carrega o conteúdo completo. Se a skill referencia arquivos adicionais, carrega apenas quando necessário.
Esse mecanismo se chama progressive disclosure — revelação progressiva de contexto — e é o que permite que o sistema escale sem sobrecarregar o agente.
├── .agents/skills/
│ ├── create-entity/
│ │ └── SKILL.md
│ ├── create-usecase/
│ │ └── SKILL.md
│ └── enforce-boundary/
│ └── SKILL.md
Para dar uma ideia geral da anatomia, veja um exemplo simples de uma skill run-lint. Todo projeto tem linter — o que muda de projeto para projeto são as regras e os comandos:
---
name: run-lint
description: "Executando lint e corrigindo erros de estilo/formatação. Use quando o usuário
pedir para rodar lint, corrigir estilo, formatar código, ou antes de finalizar qualquer PR.
Não use para erros de lógica ou build — use debug-build."
---
# Skill: Rodar Lint
## Instruções
### Passo 1: Executar o linter
- [ ] Rodar `npm run lint` na raiz do projeto
- [ ] Anotar os erros reportados (arquivo, linha, regra violada)
### Passo 2: Corrigir erros auto-fixáveis
- [ ] Rodar `npm run lint -- --fix`
- [ ] Verificar se restam erros manuais
### Passo 3: Corrigir erros manuais
- [ ] Para cada erro restante, aplicar a correção seguindo a regra indicada
- [ ] Não desabilitar regras do ESLint sem aprovação explícita do usuário
## Critical
- Nunca adicione `// eslint-disable` sem aprovação explícita. Desabilitar regras
silenciosamente esconde problemas reais e degrada a qualidade do código ao longo do tempo.
## Exemplos
### Exemplo 1: Lint pós-feature
Usuário diz: "Roda o lint antes de abrir a PR"
Ações: executa `npm run lint`, corrige auto-fixáveis, resolve manualmente o restante.
Resultado: código limpo, pronto para PR sem warnings.
## Troubleshooting
**Erro: `Parsing error: Unexpected token`**
- Causa: arquivo com sintaxe inválida (geralmente JSX sem config de parser).
- Solução: verificar `eslint.config.js` e confirmar que o parser correto está configurado.
## Performance Notes
- Sempre rode o lint completo, não apenas no arquivo alterado — mudanças podem afetar imports de outros módulos.
## Consulte também
- [enforce-boundary](../enforce-boundary/SKILL.md) — checklist de fronteiras arquiteturais
Perceba o padrão: frontmatter com name e description como campos obrigatórios (outros opcionais são license, compatibility, allowed-tools e metadata). A description é o mecanismo de triggering — o agente a lê antes de decidir se vai carregar o resto da skill. O corpo usa ## Instruções com passos numerados, ## Critical para regras de alto impacto, ## Exemplos com cenários reais, e ## Troubleshooting para os erros mais comuns. Instruções executáveis, não explicações arquiteturais.
A description merece atenção especial porque é o único campo que o agente lê antes de carregar a skill. É ela que decide se a skill vai ser acionada. O resto do arquivo — o corpo com checklists e exemplos — só entra em cena se a description convencer o agente de que aquela skill é relevante para a tarefa atual.
Isso tem implicações práticas importantes. Uma description fraca ("Skill para rodar lint") resulta em undertriggering: o agente não usa a skill mesmo quando deveria. Uma description vaga demais resulta em overtriggering: a skill é carregada em contextos errados, ocupando espaço desnecessário.
Undertriggering: é quando o agente não aciona a skill mesmo quando a tarefa se encaixa. Exemplo: o usuário pede "roda o lint antes da PR", mas a
descriptioné "Skill para lint" — o agente não tem certeza se isso inclui formatação e ignora a skill.Overtriggering: é quando o agente aciona a skill em contextos que não são ideais. Exemplo: a
descriptioné "Executando verificações de código" e o usuário pede "roda os testes" — o agente carrega a skill de lint quando deveria usar uma skill de testes.
A estrutura que funciona é: O QUE faz + QUANDO usar (frases que o usuário diria) + capacidades-chave + opcionalmente "Não use para X" se houver risco de overtriggering. Tudo isso em menos de 1024 caracteres, sem tags XML (< ou >).
Uma dica contraintuitiva: a description deve ser um pouco "empurrativa". Em vez de "Roda lint", prefira "Executando lint e corrigindo erros de estilo/formatação. Use quando o usuário pedir para rodar lint, corrigir estilo, formatar código, ou antes de finalizar qualquer PR. Não use para erros de lógica ou build." O agente tende ao undertriggering — uma cutucada a mais na description compensa esse viés.
Truque de debugging: se você suspeita que a description não está funcionando, pergunte diretamente ao agente: "Quando você usaria a skill [nome-da-skill]?". O agente vai citar a description de volta. Compare o que ele responde com o que você esperava e ajuste o texto com base na diferença. Esse método é mais rápido do que testar por tentativa e erro.
Problem-first vs. Tool-first
Antes de classificar os tipos, vale entender duas abordagens de design que o guia da Anthropic chama de problem-first e tool-first. A analogia deles é a Home Depot (loja de materiais de construção ): você pode entrar com um problema ("preciso consertar um armário") e um funcionário te aponta as ferramentas certas, ou pode escolher uma furadeira nova e perguntar como usá-la no seu caso.
- Problem-first: "Preciso implementar o CRUD de produtos" → a skill (meta-skill) orquestra as micro-skills na sequência correta. O usuário descreve o resultado; a skill lida com as ferramentas.
- Tool-first: "Tenho o MCP do Sentry conectado" → a skill ensina ao agente os workflows e boas práticas para usar aquela ferramenta. O usuário já tem acesso; a skill fornece expertise.
No contexto de repositórios (o foco deste artigo), a maioria das skills será problem-first: o dev descreve o que quer ("cria uma entidade", "implementa a feature") e a skill guia o agente pelas etapas. Skills tool-first são mais comuns quando você tem integrações MCP (Notion, Linear, Sentry, etc.) e quer padronizar como o agente usa esses serviços.
Os 3 Tipos de Skills
Nós classificamos as skills em três tipos, cada um com um propósito distinto:
Micro-skill
Operação atômica, um único nível de abstração. São as mais usadas.
Exemplos: create-entity, add-endpoint, write-unit-test, create-usecase.
Regras:
- Se precisar de exemplos longos (mais de 20 linhas de código), coloque em
references/e aponte explicitamente no corpo da skill. - O SKILL.md completo deve ter menos de 5.000 palavras — se passar disso, divida em micro-skills ou mova conteúdo para
references/.
Meta-skill
Orquestra micro-skills para executar um workflow completo. Contém a sequência de passos, não os detalhes de cada passo.
Exemplos: implement-backend-feature, implement-feature-admin.
Regra: uma meta-skill não deve ter checklists detalhados — ela aponta para as micro-skills que os têm. Inclua sempre enforce-boundary (ou equivalente) como passo final.
Constraint-skill
Contém apenas restrições e checklists de verificação. Não tem workflow, não tem passos — tem regras que nunca devem ser violadas.
Exemplos: enforce-boundary.
Regra: use ## Critical para enfatizar as regras de alto impacto — não CAPS (ALWAYS/NEVER) como substituto para explicação de contexto. CAPS é aceitável em CLAUDE.md e AGENTS.md, mas dentro do corpo de uma skill, o modelo responde melhor ao ## Critical acompanhado de uma breve explicação do porquê.
Uma recomendação forte do guia oficial da Anthropic: para validações críticas, use scripts programáticos em vez de depender apenas de instruções em linguagem natural. Código é determinístico; interpretação de linguagem não é. Uma constraint-skill como enforce-boundary pode incluir um scripts/check-boundaries.sh que faz grep por imports proibidos nos diretórios protegidos — e instrui o agente a rodar o script antes de finalizar:
# scripts/check-boundaries.sh
# Verifica imports proibidos na camada de domínio
find src/*/domain -name '*.js' | xargs grep -l \
-e "require.*express" \
-e "require.*sequelize" \
-e "from 'express'" \
-e "from 'sequelize'" \
&& echo "VIOLAÇÃO: import de infraestrutura em domain/" && exit 1 \
|| echo "OK: fronteiras respeitadas"
Isso transforma a constraint-skill de uma "sugestão forte" para uma verificação determinística. O agente pode errar ao interpretar uma regra em linguagem natural, mas não pode errar ao rodar um script que retorna exit code 1. Se o script falha, a skill instrui o agente a corrigir antes de prosseguir. Esse padrão é especialmente útil no Estágio 3.
Estrutura de uma Micro-skill
Olha a diferença estrutural. Antes era um checklist disfarçado de skill. Agora é uma skill de verdade: tem instruções com passos, tem exemplos concretos com situação real de usuário, tem troubleshooting para o erro mais comum, e tem uma seção ## Critical que explica o porquê da regra mais importante — em vez de gritar NUNCA em caps como se o desenvolvedor fosse um marido de Tiktok.
---
name: create-entity
description: "Cria ou modifica uma entidade de domínio no backend, seguindo Clean Architecture. Use quando o
usuário pedir para adicionar entidade, criar modelo de domínio, adicionar campo, ou disser 'criar X',
'novo Value Object'. Não use para criar Use Cases — use create-usecase."
---
# Skill: Criar Entidade de Domínio
## Instruções
### Passo 1: Criar a entidade (`src/{módulo}/domain/entity/{entidade}.entity.js`)
- [ ] Estende `BaseEntity` de `src/@shared/domain/entity/`
- [ ] Construtor recebe apenas primitivos ou Value Objects — nunca models do Sequelize
- [ ] Método `validate()` lança `DomainError` se dados inválidos
### Passo 2: Criar a factory (`src/{módulo}/domain/entity/{entidade}.factory.js`)
- [ ] Método estático `create(data)` instancia e valida a entidade
- [ ] Aceita dados brutos, retorna entidade validada ou lança erro
### Passo 3: Criar o schema de validação (`src/{módulo}/domain/validator/{entidade}.validator.js`)
- [ ] Usa Joi para definir o schema
- [ ] Sem imports de Express, Sequelize ou `src/models/*`
## Critical
- Nunca importe Express, Sequelize ou `src/models/*` em `domain/`. A camada de domínio não pode depender de
infraestrutura — isso é o que permite testar a lógica de negócio sem banco de dados ou HTTP.
## Exemplos
### Exemplo 1: Nova entidade de negócio
Usuário diz: "Cria a entidade Produto com nome, preço e estoque"
Ações: cria `produto.entity.js` estendendo `BaseEntity`, `produto.factory.js` com `create(data)`,
`produto.validator.js` com schema Joi.
Resultado: entidade testável, sem dependência de infraestrutura.
## Troubleshooting
**Erro: `Cannot find module 'BaseEntity'`**
Causa: import com caminho errado.
Solução: verifique `src/@shared/domain/entity/base.entity.js` e ajuste o import relativo.
## Performance Notes
- Execute os 3 passos em ordem — não pule a validação
- Não finalize sem verificar que não há imports de Express ou Sequelize
## Consulte também
- [enforce-boundary](../enforce-boundary/SKILL.md) — checklist final obrigatório
- [create-usecase](../create-usecase/SKILL.md) — próximo passo após criar a entidade
Estrutura de uma Meta-skill
Agora, observe a estrutura de uma meta-skill. Ela não tem detalhes de implementação — ela aponta para as micro-skills que têm os detalhes. O foco é a sequência e a orquestração, não o conteúdo de cada passo.
---
name: implement-backend-feature
description: Implementando feature completa no backend (entidade → use case → endpoint → testes). Use como ponto de
entrada para qualquer nova funcionalidade backend em módulo existente.
---
# Skill: Implementar Feature Backend (Meta-Skill)
## Quando usar
- Nova funcionalidade em módulo existente (não novo módulo do zero)
- Feature que envolve entidade + use case + endpoint
## Inputs necessários
- [O que você precisa saber antes de começar]
- [Spec, endpoint, entidade envolvida]
## Workflow (execute nesta ordem)
### 1. [Primeira etapa]
→ **Usar skill: [[micro-skill-1]](../[micro-skill-1]/SKILL.md)**
- [Nota específica para esta etapa, se necessário]
### 2. [Segunda etapa]
→ **Usar skill: [[micro-skill-2]](../[micro-skill-2]/SKILL.md)**
### 3. Verificação final
→ **Usar skill: [[enforce-boundary]](../enforce-boundary/SKILL.md)**
```bash
[comando de validação final]
```
Estrutura de uma Constraint-skill
Por fim, a constraint-skill. Se a micro-skill responde "como fazer X" e a meta-skill responde "em que ordem fazer X, Y e Z", a constraint-skill responde uma pergunta diferente: "o que nunca pode acontecer?"
Ela não tem workflow. Não tem passos de implementação. Tem regras de fronteira e um checklist de verificação. O agente a carrega como etapa final de qualquer operação — é o guarda na porta de saída, não o pedreiro construindo a parede.
A diferença estrutural mais importante: enquanto micro-skills e meta-skills confiam em linguagem natural para guiar o agente, a constraint-skill deve — sempre que possível — incluir validação programática. Um script bash que retorna exit code 1 é mais confiável do que uma instrução "NUNCA importe X em Y". O agente pode interpretar mal uma regra em texto, mas não pode ignorar um exit 1.
---
name: enforce-boundary
description: "Verificando fronteiras arquiteturais antes de finalizar qualquer mudança.
Use como checklist final em qualquer edição de código backend. Deve ser executada
após micro-skills e como passo final de meta-skills. Não use para validar lógica de
negócio — use write-unit-test."
---
# Skill: Enforce Boundary (Constraint-Skill)
## Quando usar
- Antes de finalizar qualquer mudança em código backend
- Como checklist final de qualquer meta-skill
- Ao revisar código de outro desenvolvedor ou agente
## Regras de Fronteira (NUNCA violar)
- `domain/`: NUNCA importe Express, Sequelize ou qualquer framework de infraestrutura
- `application/`: PODE importar `domain/`, NUNCA `infrastructure/` diretamente
- `infrastructure/`: PODE importar tudo — é a camada de borda
## Checklist de Verificação
- [ ] Arquivos em `domain/` importam apenas outros arquivos de `domain/` ou `@shared/`
- [ ] Sem imports de ORM, HTTP ou filesystem fora de `infrastructure/`
- [ ] Controllers delegam para Use Cases — sem lógica de negócio
- [ ] Testes existem para cada Use Case novo ou modificado
## Validação Automatizada
```bash
# Script determinístico — mais confiável que regras em linguagem natural
scripts/check-boundaries.sh
```
Se o script retornar erro, corrija antes de prosseguir.
## Critical
- Validações programáticas (scripts) são preferíveis a instruções em linguagem natural
para verificações de fronteira. Código é determinístico; interpretação de linguagem não é.
- Se o script retornar erro, o agente DEVE corrigir antes de finalizar a tarefa.
Note a ausência de ## Instruções com passos numerados — isso é intencional. A constraint-skill não guia uma construção, ela audita o resultado. A seção ## Regras de Fronteira substitui os passos: em vez de "faça isso", ela diz "isso nunca pode existir". E a seção ## Validação Automatizada é o que transforma a skill de uma "sugestão forte" em uma verificação determinística — o ponto que já discutimos na definição dos tipos.
Regras de Autoria
Nomenclatura: verbo-substantivo, em inglês, kebab-case.
- ✅
create-entity,add-endpoint,write-unit-test - ❌
entity-creation,endpoint-addition,unit-test-writing(tecnologia-centric, passivo) - ❌
backend-entity,http-endpoint(tecnologia-centric)
O problema de nomes passivos ou tecnologia-centric é que eles não descrevem a ação que o agente deve executar. "Create-entity" diz claramente o que fazer. "Entity-creation" é mais vago — o agente pode não entender se é um comando, um conceito, ou uma categoria de skills.
Frontmatter permitido: O frontmatter de uma skill aceita os seguintes campos:
name— obrigatório, kebab-case, igual ao nome da pastadescription— obrigatório, < 1024 chars, sem tags XMLlicense— opcional (ex: MIT, se for open-source)compatibility— opcional (ex:claude-code, 1-500 chars)allowed-tools— opcional (restringe ferramentas — ex:"Bash(python:*) WebFetch")metadata— opcional, campos livres (version, author, category, tags)
Proibido: tags XML no frontmatter, campos não listados acima (ex: triggers: não existe), nomes com prefixo claude ou anthropic.
Seção ## Instruções: use passos numerados com ações concretas. "Crie o arquivo X com Y" é melhor que "é necessário criar o arquivo X". O agente segue melhor imperativos do que descrições.
Seção ## Critical: use para regras que, se violadas, causam bugs graves ou violações de arquitetura. Explique brevemente o porquê — não para justificar ao agente, mas porque o modelo entende contexto e vai aplicar a regra melhor se souber a consequência de violá-la. Evite CAPS (ALWAYS/NEVER) como substituto para essa seção.
Seção ## Exemplos: inclua ao menos um exemplo concreto. O formato que funciona: "Usuário diz: [frase real]" → "Ações: [lista]" → "Resultado: [o que o usuário recebe]". Exemplos de código com mais de 20 linhas vão em references/.
Seção ## Troubleshooting: documente os 2-3 erros mais comuns que acontecem ao executar a skill. Formato: Erro + Causa + Solução.
Seção ## Performance Notes: use quando o agente tende a pular etapas. "Execute cada passo em ordem, sem pular validações." Não é obrigatório, mas resolve problemas de preguiça agêntica (não, oferecer um aumento de salário ou café com monster de mango loco não é uma opção).
Uma nuance importante do guia oficial da Anthropic: frases de encorajamento como "Take your time" e "Do not skip validation steps" são mais efetivas quando adicionadas no prompt do usuário do que quando estão no SKILL.md. Se o agente insiste em pular etapas mesmo com ## Performance Notes, tente incluir a instrução no prompt da tarefa.
Referências cruzadas: uma skill pode referenciar outra, mas máximo um nível de profundidade. Não crie cadeias: A → B → C → D. Se isso acontecer, A é uma meta-skill que deveria apontar diretamente para B, C e D. Lembre-se da regra: Grafos cíclicos são uma forma de invocação do mal.
Nunca duplique: se a regra já está no CLAUDE.md ou AGENTS.md, não repita na skill. A skill adiciona detalhe procedural, não repete contexto global.
Estrutura de Diretórios
As skills ficam organizadas no diretório .agents/skills/. Ferramentas específicas, como Copilot ou Claude, têm symlinks para esse diretório.
O references/ é o terceiro nível do sistema de progressive disclosure. A lógica funciona assim:
- Sempre no contexto: o frontmatter (
name+description) de todas as skills disponíveis — são ~100 palavras por skill - Sob demanda: o corpo completo do SKILL.md, quando a skill é ativada — ideal abaixo de 500 linhas
- Apenas quando explicitamente referenciado: arquivos em
references/— sem limite de tamanho, carregados só quando a skill instrui o agente a ler
Isso significa que você pode ter exemplos longos (50+ linhas de código), templates completos ou documentação de referência em references/ — e eles só entram no contexto quando o agente realmente precisar. Não poluem o contexto de quem está fazendo outra tarefa.
Regra prática: se um exemplo de código tem mais de 20 linhas, vai para references/. O SKILL.md principal mantém apenas o essencial acionável.
.agents/skills/
├── create-entity/
│ ├── SKILL.md ← carregado quando a skill é ativada
│ └── references/
│ └── entity-example.js ← carregado só quando o SKILL.md instrui
├── add-endpoint/
│ ├── SKILL.md
│ └── references/
│ └── controller-patterns.md
├── enforce-boundary/
│ ├── SKILL.md ← constraint-skill
│ └── scripts/
│ └── check-boundaries.sh ← validação determinística
└── implement-backend-feature/
└── SKILL.md ← meta-skill que aponta para as outras
Além de references/, skills podem incluir scripts/ (código executável: Python, Bash, etc.) e assets/ (templates, imagens, arquivos de apoio). A regra é a mesma: só entram no contexto quando a skill instrui o agente a usá-los.
Por Que Skills Pequenas Vencem
Quando você tem uma skill de 200 linhas que cobre "todo o backend Clean Architecture", o agente carrega 200 linhas para criar uma entidade — quando precisava de 40.
Quando você tem create-entity (50 linhas) e add-endpoint (45 linhas) separadas, o agente carrega 50 linhas para criar a entidade, e 45 para adicionar o endpoint. Total: menos contexto, mais foco, melhor resultado.
Como o Agente Decide Qual Skill Usar
Aqui está o que acontece nos bastidores quando você pede algo ao agente:
- O agente tem na memória ativa o frontmatter (
name+description) de todas as skills disponíveis - Para cada prompt do usuário, ele avalia qual description mais se encaixa com a tarefa
- Se a description de uma skill corresponde, ele carrega o corpo completo do SKILL.md
- Se o corpo do SKILL.md referencia arquivos em
references/, carrega apenas os que a tarefa exige
A consequência prática é que a description não é só metadado — é o único mecanismo de seleção. Uma skill com description ruim nunca vai ser usada, não importa quão bom seja o resto do conteúdo. É como ser um desenvolvedor brilhante, mas ter um péssimo currículo: ninguém te chama para a entrevista.
A Divisão de Responsabilidades: docs/ vs skills/
Uma confusão frequente é onde vai cada tipo de informação. A distinção é simples:
docs/ é para referência humana. Nada dentro de docs/ deve ser carregado como contexto de agente. Um exemplo de estrutura recomendada:
docs/specs/{módulo}/— specs funcionais por módulo: user stories, contrato de endpoints, modelo de domínio, ADR do módulodocs/adr/— decisões arquiteturais globais (cross-cutting, afetam o projeto inteiro)docs/runbooks/— procedimentos operacionais: deploy, troubleshooting, acesso a banco, rollbackdocs/input/— referências externas, pesquisa, materiais de apoio
skills/ é para instrução do agente. Se algo é procedural e o agente precisa executar, é uma skill.
A regra prática para decidir onde algo vai:
| Pergunta | Destino |
|---|---|
| "Como eu faço X?" (humano consultando) | docs/runbooks/ |
| "O que o agente deve fazer ao executar X?" | skills/ |
| "Por que decidimos usar X?" | docs/adr/ ou docs/specs/{módulo}/adr-0000-[adr-name].md |
| "O que o agente deve SEMPRE/NUNCA fazer?" | CLAUDE.md ou AGENTS.md |
| "Qual foi a história do requisito Y?" | docs/specs/{módulo}/user-stories/ |
O anti-padrão: colocar procedimentos em docs/ e referenciar essas páginas como contexto para o agente. Isso faz o agente carregar documentação de onboarding quando deveria ter uma skill de 50 linhas.
Índice de documentação para lazy-loading
Para evitar que o arquivo global vire um monólito de contexto, mantenha no CLAUDE.md/AGENTS.md apenas um índice curto de documentação. O agente consulta o detalhamento sob demanda.
## Documentation
Documentação detalhada em `docs/`. Ler sob demanda.
| Tópico | Local |
| ----------------------- | -------------------- |
| Arquitetura | `docs/architecture/` |
| App Web | `docs/apps/website/` |
| API | `docs/apps/api/` |
| Deploy | `docs/deployment/` |
| Guia de desenvolvimento | `docs/development/` |
A lógica é simples: índice sempre carregado; conteúdo denso só quando a tarefa exigir.
7. Memória Estruturada: O Agente que Lembra
O Problema da Amnésia
Sabe aquele amigo que bebe demais numa sexta e na segunda jura que não fez nada? "Eu falei isso? Não lembro." Pois é. Seu agente faz a mesma coisa. Toda sessão é ressaca total: memória zerada.
Isso é intrínseco à forma como os LLMs funcionam — eles não têm memória persistente nativa.
Sem estrutura de memória explícita:
- O agente questiona decisões já tomadas ("posso usar Redux aqui?", quando a decisão de migrar para Zustand foi tomada há meses)
- O agente repete erros já corrigidos (porque não sabe que o erro aconteceu)
- O agente explora os mesmos arquivos toda sessão para entender o projeto
- Decisões importantes ficam apenas no chat — e desaparecem com a janela
Os 2 Tipos de Memória
Memória de Sessão (gerenciada pela ferramenta)
Claude Code, por exemplo, mantém um arquivo de memória automático em ~/.claude/projects/{projeto}/memory/MEMORY.md. Ele gerencia isso sozinho, atualizando entre sessões.
Características:
- Automática — o agente decide o que salvar
- Local na máquina — não sincroniza com o repositório
- Pessoal — reflete as preferências e descobertas do dev que usa a ferramenta
Use para: preferências pessoais de workflow, descobertas específicas da sua sessão.
Memória de Projeto (gerenciada pelo time)
Um arquivo memory/MEMORY.md commitado no repositório. Editado pelo time (e pelo agente, quando instruído).
Características:
- Intencional — o time decide o que salvar
- Compartilhada — disponível para todos os devs e todos os agentes
- Durável — sobrevive a troca de máquina, onboarding de novo dev, mudança de ferramenta
Use para: decisões arquiteturais, padrões confirmados, bugs conhecidos, estado de migrations.
Estrutura Recomendada para memory/MEMORY.md
# Memória do Projeto
## Decisões Arquiteturais
- **[2026-01]** Adotamos Joi para validação no domain layer.
Contexto: express-validator criava acoplamento com Express na camada errada.
Consequência: todo novo validator usa Joi, nunca express-validator.
- **[2026-02]** Módulo de Pagamentos permanece em legado até março/2026.
Contexto: integração ativa com gateway antigo, refatoração planejada para abril.
Consequência: não criar novos endpoints em Clean Architecture para pagamentos ainda.
## Padrões Confirmados (reutilize estes)
- **Facade Factory:** toda operação vai por `{módulo}.facade.factory.js` → `{módulo}.facade.js` → UseCase
- **Mapeamento de erro:** usar lookup-table em `errorHandler.js`, não if-else em cadeia
## Problemas Conhecidos e Workarounds
- **Testes de integração do módulo de autenticação:** precisam de `jest.useFakeTimers()`.
Causa: token de refresh depende de `Date.now()`.
## Estado de Migração Legado → Clean Architecture
| Módulo | Estado |
| ---------- | ----------------------------- |
| Usuários | ✅ Migrado |
| Produtos | ✅ Migrado |
| Pedidos | ⚠️ Em progresso (50%) |
| Pagamentos | ❌ Legado (planejado abr/2026) |
Regras de Manutenção
-
Não duplique o CLAUDE.md ou AGENTS.md — memória é para o que muda, não para o que é estável.
-
Apenas fatos confirmados — não especulações. "Talvez devêssemos usar Redis" não é memória, é uma opinião.
-
Mantenha conciso — menos de 200 linhas. Ferramentas como Claude Code podem truncar após esse limite.
-
Crie arquivos de overflow — se um tópico precisa de mais espaço, crie
memory/patterns.md,memory/migrations.md. O MEMORY.md principal lista os tópicos e aponta para os arquivos. -
Date as decisões —
[2026-01]ajuda a entender o contexto histórico e identificar o que pode ter mudado.
Como Referenciar a Memória
No CLAUDE.md:
## Memória
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
No AGENTS.md:
## Memória do projeto
- `memory/MEMORY.md` — decisões, padrões confirmados, bugs conhecidos
- Ler no início de sessões que envolvam arquitetura ou módulos em migração
8. Multi-Agente na Prática
O Desafio Real
Quando você usa Claude Code pela manhã, Copilot na tarde e Codex para code review, cada ferramenta constrói contexto de formas diferentes. Sem uma estratégia unificada, você terá:
- Claude Code seguindo uma regra que o Copilot desconhece
- Regras duplicadas em três arquivos que ficam desatualizadas independentemente
- O Codex propondo uma refatoração que viola os padrões estabelecidos — porque não tinha como saber quais eram
A Estratégia das Três Camadas na Prática
Camada 1 — Base Universal (AGENTS.md)
Este arquivo é a constituição do projeto. Regras que estão aqui valem para todos — inclusive a lista de skills disponíveis, que é o catálogo central.
# AGENTS.md — MeuProjeto
## Arquitetura
Aplicação Node.js/Express em migração MVC → Clean Architecture.
- Código novo: src/{módulo}/domain|application|infrastructure
- Legado: src/controllers/, src/models/
## Regras Universais
- NUNCA importe Express ou Sequelize em domain/ ou application/
- SEMPRE estenda BaseEntity para novas entidades
- SEMPRE use Facade entre Controller e UseCases
- NUNCA adicione lógica de negócio em Controllers
- SEMPRE escreva testes unitários para novos Use Cases
## Skills disponíveis
- `/create-entity` — Criar/modificar entidade de domínio
- `/create-usecase` — Criar Use Case + teste unitário
- `/add-endpoint` — Adicionar endpoint HTTP
- `/implement-backend-feature` — Feature completa (meta-skill)
- `/enforce-boundary` — Verificar fronteiras (constraint-skill)
## Memória
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
Camada 2 — Específica por Ferramenta
Cada ferramenta tem seu arquivo específico, mas ele apenas complementa — nunca duplica. Note que nenhum dos exemplos abaixo repete as regras ou a lista de skills — eles referenciam o AGENTS.md.
Exemplo de CLAUDE.md:
# MeuProjeto API
Node.js/Express, Clean Architecture (migração desde 2025).
Ver AGENTS.md para arquitetura, regras e lista de skills.
## Comandos
- `npm run dev` — Iniciar em desenvolvimento
- `npm run test:unit` — Apenas testes unitários
- `npm run lint` — ESLint
## Memória
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
Exemplo de copilot-instructions.md:
# .github/copilot-instructions.md
Ver AGENTS.md para arquitetura, regras universais e lista de skills.
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
Perceba: o copilot-instructions.md é quase um stub. Ele existe para que o Copilot saiba onde procurar — as regras e skills vivem no AGENTS.md. Se você precisar de instruções específicas para o Copilot (como regras de applyTo em .github/instructions/), adicione apenas o que é exclusivo dessa ferramenta.
Camada 3 — Skills (disponível onde suportado)
A fonte de verdade é .agents/skills/. Cada ferramenta que tem pasta nativa própria recebe um symlink apontando para ela:
- GitHub Copilot lê
.github/skills/nativamente → criamos symlink.github/skills/ → ../.agents/skills/ - Claude Code lê
.claude/skills/nativamente → criamos symlink.claude/skills/ → ../.agents/skills/ - Codex, Gemini, Cursor leem
.agents/skills/nativamente — sem symlink necessário
Assim, ao adicionar uma skill em .agents/skills/, ela fica disponível para todas as ferramentas automaticamente.
Onde nenhum mecanismo nativo de skills existe, o AGENTS.md faz o papel de "skill simplificada" — descreve o workflow em texto, sem a progressividade do mecanismo de skills.
Exemplo de Fluxo Real
Desenvolvedor pede para Claude Code: "Adiciona um endpoint GET /v2/orders/:id que retorna um pedido pelo ID."
O que acontece:
- Claude lê
CLAUDE.md→ sabe que é Clean Architecture, sabe os comandos - Claude lê
AGENTS.md→ sabe as regras, vê a lista de skills - Claude identifica que a tarefa combina com
/add-endpoint - Claude carrega
add-endpoint/SKILL.md→ tem o checklist completo - Claude executa: Controller → Validator → Route → Composer → OpenAPI
- No final, Claude executa
/enforce-boundary→ verifica que nada violou as fronteiras
O desenvolvedor não precisou explicar o workflow. Não precisou listar os arquivos que precisam ser criados. Não precisou lembrar de rodar a validação OpenAPI. Tudo estava na skill.
Garantindo Consistência Entre Ferramentas
Regra 1: O AGENTS.md é a fonte de verdade para regras universais. Quando uma regra muda, ela muda no AGENTS.md. Os outros arquivos não precisam ser atualizados.
Regra 2: Nunca coloque uma regra em dois arquivos. Se está no AGENTS.md, o CLAUDE.md não repete — ele referencia.
Regra 3: Quando uma ferramenta não suporta skills, o AGENTS.md e o arquivo específico devem ter as regras mais críticas explícitas (não apenas "ver skills").
Regra 4: Teste a consistência regularmente. Abra cada ferramenta e peça a mesma operação. O resultado deve ser estruturalmente idêntico, mesmo que o código gerado varie.
9. O Skill Graph: Estágio 3 na Prática
O Conceito
Se você chegou até aqui sem fechar a aba, parabéns. Esse é o final boss.
No Estágio 2, você tem skills isoladas. O desenvolvedor invoca a skill certa no momento certo.
No Estágio 3, as skills se conhecem. Uma meta-skill orquestra micro-skills. Uma constraint-skill é verificada sempre. O repositório se torna um grafo de capacidades — e o agente navega esse grafo de forma autônoma.
Anatomia de um Skill Graph
implement-backend-feature (meta-skill)
├── [1] create-entity (micro-skill)
│ └── verifica: enforce-boundary
├── [2] create-usecase (micro-skill)
│ └── verifica: enforce-boundary
├── [3] add-endpoint (micro-skill)
│ └── verifica: enforce-boundary
└── [verificação final] enforce-boundary (constraint-skill)
└── checa todas as fronteiras antes de finalizar
Se você já jogou RPG, pense nas skills como a árvore de habilidades. A meta-skill é a classe, as micro-skills são as habilidades individuais, e a constraint-skill é o mestre que não te deixa usar magia negra.
Quando o desenvolvedor pede "implementa o CRUD de produtos", o agente:
- Identifica que a tarefa combina com
implement-backend-feature - Carrega a meta-skill
- Segue o workflow: create-entity → create-usecase → add-endpoint
- Em cada passo, usa a micro-skill correspondente
- No final, executa enforce-boundary
O desenvolvedor não gerenciou o workflow. O workflow estava no grafo.
Mapeando sua Arquitetura em Skills
"Tá, bonito o conceito. Mas como eu sei qual skill pertence a qual parte do meu projeto?"
A resposta é simples: cada camada da sua arquitetura tem um tipo de operação predominante. A tabela abaixo mapeia camadas em skills — se o seu projeto segue outra arquitetura, a lógica é a mesma: identifique a operação dominante de cada camada e crie (ou atribua) uma skill pra ela.
Para Node.js + Express + Clean Architecture:
| Camada | Arquivo | Skill Responsável |
|---|---|---|
| Domain | src/{módulo}/domain/entity/ | create-entity |
| Domain | src/{módulo}/domain/validator/ | create-entity |
| Application | src/{módulo}/application/usecases/ | create-usecase |
| Application | src/{módulo}/application/facade/ | create-usecase |
| Infrastructure | src/{módulo}/infrastructure/http/controller/ | add-endpoint |
| Infrastructure | src/{módulo}/infrastructure/http/routes/ | add-endpoint |
| Infrastructure | src/{módulo}/infrastructure/http/composer/ | add-endpoint |
| Cross-cutting | Verificação final de qualquer mudança | enforce-boundary |
Para React + Clean Architecture (frontend):
| Camada | Arquivo | Skill Responsável |
|---|---|---|
| API Client | src/features/{módulo}/api/ | create-frontend-api-client |
| Model/Contratos | src/features/{módulo}/model/ | frontend-model-contracts |
| Hooks | src/features/{módulo}/hooks/ | frontend-hooks-react-query |
| Components | src/features/{módulo}/components/ | create-frontend-component |
| Pages | src/features/{módulo}/pages/ | frontend-pages-shell |
| Testes | Qualquer camada | create-frontend-test |
| Meta | Feature completa | implement-feature-frontend |
O SDLC Executável
Se você já trabalhou em empresa que tinha um processo de desenvolvimento documentado num Confluence empoeirado que ninguém seguia, vai entender a beleza dessa parte.
O Skill Graph transforma o SDLC (Software Development Lifecycle) em algo que não depende de boa vontade humana para ser seguido. Para cada tipo de operação, existe um caminho claro — e o agente segue esse caminho porque ele está codificado nas skills, não num wiki que ninguém lê:
Feature de backend:
implement-backend-feature
→ create-entity (se nova entidade)
→ create-usecase
→ add-endpoint
→ enforce-boundary
Correção de bug em legado:
diagnose-legacy-bug (skill de diagnóstico)
→ apply-fix
→ enforce-boundary
Feature de frontend:
implement-feature-frontend
→ create-frontend-api-client (funções HTTP por intenção)
→ frontend-model-contracts (contratos de dados / normalização)
→ frontend-hooks-react-query (hooks com queryKey + invalidação)
→ create-frontend-component (componentes de UI isolados)
→ frontend-pages-shell (page shell padrão)
→ create-frontend-test (testes de hook/page/component)
Cada um desses caminhos pode ser codificado em uma meta-skill. O agente segue o caminho sem precisar de instrução a cada passo.
Como Transicionar do Estágio 2 para o Estágio 3
Se você já tem skills funcionando isoladamente (Estágio 2), conectá-las num grafo não é uma refatoração — é uma evolução incremental. Você não joga fora o que construiu; você liga os fios.
Passo 1: Identifique as 5-7 operações atômicas que acontecem em toda PR. Exemplo: criar entidade, criar use case, adicionar endpoint, escrever teste unitário.
Passo 2: Para cada operação, verifique se existe uma micro-skill. Se não existir, crie (40-60 linhas, checklist, referências).
Passo 3: Crie uma constraint-skill com as regras de fronteira arquitetural. Esta skill será executada no final de qualquer mudança relevante.
Passo 4: Crie uma meta-skill para cada tipo de feature que você desenvolve. A meta-skill referencia as micro-skills na ordem correta.
Passo 5: Atualize o AGENTS.md com o grafo de skills. Documente quais skills existem, o que cada uma faz, e as relações entre elas.
Passo 6: Teste em sessão limpa. Abra uma nova sessão, peça uma feature completa. O agente deve seguir o workflow sem instrução adicional.
Métricas do Estágio 3
Como saber se você chegou lá:
- O agente não explora mais de 5 arquivos antes de começar a implementar (porque o contexto estava nos arquivos de contexto, não no código)
- Nenhuma PR com violação de fronteira arquitetural (a constraint-skill pegou antes)
- O custo de tokens por feature é estável — não cresce com o tamanho do projeto
- Devs novos na equipe (humanos ou agentes) produzem código aderente aos padrões na primeira sessão
10. Guia Passo a Passo: Da Fase 0 à Fase 3
Um esclarecimento antes de começar: na Seção 3, definimos Estágios (1, 2 e 3) como níveis de maturidade — onde o projeto está. Aqui, usamos Fases (0, 1, 2 e 3) como etapas de implementação — o que você faz pra chegar lá. A Fase 1 te leva ao Estágio 1–2, a Fase 2 ao Estágio 2, e a Fase 3 ao Estágio 3. A Fase 0 é o diagnóstico — porque, ao contrário do que dizem, pular o diagnóstico e sair implementando não é agilidade, é imprudência.
E o mais importante: você não precisa fazer tudo de uma vez. Cada fase tem ROI imediato. Aqui você pode ser preguiçoso e ir por partes — cada etapa já melhora o dia a dia.
Fase 0 — Diagnóstico
Antes de sair mexendo no paciente, faça como um bom médico: diagnóstico completo. Sentar na mesa da sala sem lavar as mãos e abrir a barriga do paciente com um facão de cozinha não é cirurgia, é crime.
Entenda o estado atual do projeto: onde estão os arquivos de contexto, quais regras estão espalhadas, quais operações são mais frequentes, onde as violações arquiteturais acontecem.
Checklist de diagnóstico:
- Listar todos os arquivos de contexto existentes (
README,AGENTS.md,CLAUDE.md,.github/*,.cursorrules) - Contar linhas de cada arquivo — anotar os que têm mais de 100 linhas
- Identificar qual ferramenta lê qual arquivo (use a tabela da Seção 4)
- Listar as 5-10 operações que o agente mais executa (criar entidade, adicionar endpoint, escrever teste...)
- Identificar as violações arquiteturais mais recentes — onde elas aconteceram?
- Verificar se existe
memory/MEMORY.mdcommitado — e se está sendo mantido - Avaliar: qual Estágio é o projeto? (tabela da Seção 3)
- Auditar a pasta
docs/: verificar se há procedimentos que deveriam ser skills, e specs que deveriam estar emdocs/specs/{módulo}/
Saída esperada: uma lista priorizada de problemas e uma foto clara do estado atual.
Fase 1 — Fundação
Aqui é onde o agente deixa de ser um bêbado com amnésia e começa a lembrar pelo menos quem ele é. O objetivo é garantir que, em toda sessão nova, ele tenha o mínimo necessário pra não perguntar "o que é esse projeto?" pela centésima vez.
Checklist:
- Criar
CLAUDE.mdusando o template da Seção 5 (menos de 80 linhas) - Criar ou revisar
AGENTS.md(menos de 60 linhas) - Para cada arquivo de instructions com mais de 100 linhas:
- Remover todas as explicações e justificativas
- Manter apenas regras imperativas (NEVER/ALWAYS)
- Mover exemplos de código para
docs/ou parareferences/dentro de skills - Meta: menos de 100 linhas por arquivo
- Criar
memory/MEMORY.mdcom decisões arquiteturais existentes (commitado no repositório) - Verificar que não há regras duplicadas entre
CLAUDE.md,AGENTS.mdeinstructions/
Validação: Abra uma nova sessão, não forneça contexto adicional, peça ao agente para descrever a arquitetura do projeto. Ele deve responder corretamente com base apenas no CLAUDE.md e AGENTS.md.
Fase 2 — Skills Estruturadas
Se a Fase 1 ensinou o agente a não bater nas paredes, a Fase 2 é onde ele aprende as rotas. O objetivo é que as operações mais frequentes do projeto tenham skills dedicadas — pra que o agente pare de improvisar e comece a seguir um roteiro testado.
Checklist:
- Listar as 5 operações atômicas mais repetidas no projeto
- Para cada operação, verificar se existe uma micro-skill
- Criar as micro-skills faltantes (40-60 linhas, usando a estrutura da Seção 6)
- Criar uma constraint-skill para as regras de fronteira arquitetural
- Atualizar o
AGENTS.mdcom a lista de skills e seus nomes corretos - Verificar que cada skill tem seção "Quando usar" com frases naturais (não técnicas)
- Verificar que checklists têm
[ ]e itens concretos e verificáveis
Validação: Abra uma nova sessão, peça uma operação simples (ex: "cria uma nova entidade de domínio para Produto"). O agente deve identificar e usar a micro-skill correspondente sem instrução adicional.
Dica: use o skill-creator. O Claude tem uma skill built-in chamada skill-creator, disponível tanto no Claude.ai quanto no Claude Code. Ela gera skills a partir de descrições em linguagem natural, revisa skills existentes e sugere melhorias. Use-a como atalho para criar as primeiras micro-skills: "Use the skill-creator skill to help me build a skill for [operação]". É possível construir e testar uma skill funcional em 15-30 minutos com essa ferramenta.
Métricas por skill individual. Além da validação geral, teste cada skill isoladamente:
- Triggering: rode 10-20 queries que deveriam acionar a skill + 5-10 que não deveriam. Meta: 90% de acerto.
- Eficiência: compare a mesma tarefa com e sem skill habilitada. Conte tool calls e tokens consumidos.
- Consistência: execute o mesmo pedido 3-5 vezes. Os resultados devem ter estrutura consistente.
Essas métricas são aspiracionais — benchmarks, não thresholds rígidos. Mas dão uma referência concreta para iterar.
Fase 3 — Skill Graph
Esse é o nível em que o agente para de seguir ordens e começa a seguir processos. Você não diz "cria a entidade, depois o use case, depois o endpoint". Você diz "implementa a feature de produtos" e ele sabe o que fazer — porque o caminho está no grafo de skills.
Checklist:
- Criar meta-skills para os workflows mais comuns (feature backend, feature frontend)
- Cada meta-skill referencia as micro-skills na ordem correta
- A constraint-skill é referenciada no final de cada meta-skill
- Atualizar
AGENTS.mdcom o grafo de skills (qual skill chama qual) - Verificar que as skills existentes não têm informação redundante com o CLAUDE.md
- Testar o skill graph em sessão limpa:
- Pedir uma feature completa de backend
- O agente deve seguir o workflow sem instrução a cada passo
- Verificar que o agente executou a constraint-skill no final
Validação: Feature completa (entidade + use case + endpoint + testes) implementada em uma sessão limpa, seguindo exatamente os padrões do projeto, sem violações arquiteturais, sem instrução manual de workflow.
Métricas de Validação por Fase
| Fase | O agente deve... |
|---|---|
| Fase 1 | Não questionar arquitetura em sessão nova |
| Fase 2 | Usar micro-skills corretas sem instrução adicional |
| Fase 3 | Executar features completas seguindo workflow automaticamente |
Bônus: Matriz de Modelo por Tipo de Tarefa
Isso não faz parte das Fases, mas é uma consequência natural de ter o contexto organizado: quando você sabe exatamente o que cada tarefa exige, pode escolher o modelo certo pro trabalho — em vez de usar canhão pra matar mosca.
| Tipo de tarefa | Classe de modelo recomendada | Exemplo prático |
|---|---|---|
| Varredura de arquivos, discovery, lint, formatação, docs | Rápido/econômico | Claude Haiku |
| Implementação padrão, testes, investigação de bug | Intermediário | Claude Sonnet |
| Refatoração multi-arquivo complexa, decisão arquitetural, conflitos difíceis | Alta capacidade | Claude Opus |
O princípio é agnóstico de ferramenta: não usar modelo “martelo hidráulico” para tarefa simples. Registrar essa matriz no CLAUDE.md reduz custo sem perder qualidade.
11. Armadilhas e Anti-Padrões
Anti-padrão 1: A Dissertação no Arquivo de Contexto
O problema: Regras em arquivos globais (CLAUDE.md, AGENTS.md) que vêm embrulhadas em parágrafos de justificativa, histórico e trade-offs — a ponto de a instrução acionável ficar soterrada.
## Regras
Use a classe BaseEntity porque ela oferece serialização automática,
integração transparente com o ORM e facilita a escrita de testes unitários,
pois desacopla a lógica de negócio do framework de persistência.
Historicamente, tentamos herdar de ActiveRecord, mas isso gerou acoplamento
excessivo com o banco na camada de domínio. Após três sprints de refatoração,
o time decidiu padronizar BaseEntity como classe base...
O que acontece: O agente processa o parágrafo inteiro como contexto genérico. A instrução ("use BaseEntity") compete com a narrativa ao redor. Multiplique isso por 15-20 regras e o arquivo global vira um ensaio — não um manual de operações.
Isso não quer dizer que explicar o "porquê" seja errado. Uma consequência breve na linha da regra ("SEMPRE estenda BaseEntity — herdar de ActiveRecord acopla domínio ao banco") ajuda o agente a aplicar a regra com mais inteligência em casos ambíguos. O problema é quando a justificativa vira dissertação e ocupa mais espaço que a própria instrução.
A regra: Em arquivos globais, a justificativa não pode ser maior que a instrução. Se precisar de mais de uma linha de "porquê", mova para docs/ ou para o ## Critical da skill relevante — onde o agente carrega o contexto no momento certo, não em toda sessão.
Anti-padrão 2: O Arquivo Monstro
O problema: Um arquivo de contexto (AGENTS.md, CLAUDE.md, instructions) com 200, 300, 400 linhas. Frequentemente o resultado de meses de adições incrementais sem remoções equivalentes.
Sintomas:
- O arquivo tem seções de "por que tomamos essa decisão em 2024"
- Existem exemplos de código completos (30-50 linhas de código em um arquivo de contexto)
- Tem instruções de onboarding para humanos junto com regras para o agente
A regra: Mais de 150 linhas é um sinal de alerta. Mais de 200 linhas é quase certamente um problema. Revise e distribua para os arquivos corretos (skills, docs, memory).
Anti-padrão 3: A Regra Duplicada
O problema: A mesma regra em três lugares:
- CLAUDE.md: "NUNCA importe Express em domain/"
- AGENTS.md: "Não importar Express nas camadas de domínio"
- backend-clean.instructions.md: "A camada de domínio não deve depender de Express..."
O que acontece: Quando a regra muda (ex: adicionar Fastify à lista de proibidos), você precisa atualizar três lugares. Inevitavelmente, um fica desatualizado.
A regra: Cada regra tem UM único lugar de verdade. Os outros arquivos referenciam com "ver AGENTS.md para regras completas".
Anti-padrão 4: A Skill Genérica Demais
O problema: Uma skill que tenta executar múltiplas operações não relacionadas no mesmo SKILL.md, sem delegar.
---
name: backend-tasks
description: Tarefas de backend incluindo criação de entidades, endpoints, testes e migração.
---
# Skill: Backend Tasks
## Quando usar
- Criar entidade
- Adicionar endpoint
- Escrever teste
- Migrar legado
O que acontece: O agente que precisa criar uma entidade carrega contexto sobre endpoints, testes e migração que não precisa. O contexto extra reduz o foco — e a taxa de sucesso.
O problema não é uma meta-skill que redireciona para micro-skills focadas — isso é o padrão correto. O problema é uma skill que tenta executar múltiplas operações não relacionadas no mesmo SKILL.md, sem delegar. Se o ## Workflow da skill for "faça A, depois B, depois C" onde A, B e C são operações distintas que têm suas próprias micro-skills, essa skill deveria ser uma meta-skill que aponta para as micro-skills de A, B e C — não uma skill que descreve os três procedimentos em linha.
A regra: Uma skill, uma operação. Se cobrir mais de duas operações, divida — ou transforme em meta-skill que delega.
Anti-padrão 5: A Memória Volátil
O problema: Decisões arquiteturais importantes existem apenas no chat, em comentários de PR, ou nos arquivos locais do Claude Code (não commitados).
O que acontece: Na próxima sessão, o agente não tem acesso a essas decisões. Ele pode questionar novamente uma decisão já tomada, ou propor uma abordagem que o time já descartou.
A regra: Toda decisão arquitetural importante vai para memory/MEMORY.md (commitado no repositório). Se não está commitado, não é memória do projeto — é memória pessoal.
Anti-padrão 6: O Multi-Agente Desconexo
O problema: Claude Code tem um conjunto de regras, GitHub Copilot tem outro, e eles não conversam. Uma ferramenta permite o que a outra proíbe.
O que acontece: O desenvolvedor que usa Claude Code pela manhã tem PRs arquiteturalmente corretas. O que usa Copilot à tarde tem violações — porque o Copilot não sabia das regras que estavam apenas no CLAUDE.md.
A regra: AGENTS.md é a fonte de verdade universal. Todos os outros arquivos de contexto referenciam o AGENTS.md, nunca duplicam suas regras. Quando uma regra muda, muda em um único lugar.
12. Conclusão e Próximos Passos
A Jornada em Perspectiva
Você começou o artigo com um agente que é como um júnior que acabou de chegar no time: funciona às vezes; é capaz, mas imprevisível; dependente de ordens bem formuladas e começa do zero em cada sessão.
O caminho que percorremos:
- Estágio 1: O agente trabalha no escuro, sem estrutura. Você compensa no prompt.
- Estágio 2: Há estrutura, mas incompleta. O agente funciona quando você sabe qual skill invocar.
- Estágio 3: O repositório é um grafo de capacidades. O agente navega o grafo. Você descreve o objetivo.
O Insight Central
O modelo não muda. O que muda é o ambiente que você cria.
Um LLM de última geração sem contexto estruturado produz resultados medíocres. O mesmo LLM com um CLAUDE.md bem escrito, skills focadas e memória estruturada produz resultados consistentemente acima da média.
Você não está programando o agente. Você está curando o ambiente em que ele raciocina. Seu trabalho não é mais construir o produto, mas configurar a fábrica que constrói o produto.
Por Que Vale o Investimento
Os números do SkillsBench (fev/2026) são claros: +16,2 pontos percentuais de taxa de sucesso com skills bem curadas. Em termos práticos, isso significa:
- Menos PRs com correções de arquitetura
- Menos sessões que precisam de re-trabalho
- Custo de tokens estável (não cresce com o projeto)
- Onboarding de novos devs (e novos agentes) mais rápido
O investimento em context engineering se paga a cada feature, não apenas na feature que o justificou.
Próximos Passos Concretos
Esta semana (Fase 0 + Fase 1):
- Rode o diagnóstico (checklist da Seção 10 — Fase 0)
- Crie o
CLAUDE.mdusando o template da Seção 5 - Revise ou crie o
AGENTS.md - Reduza os arquivos de instructions mais longos
Na próxima semana (Fase 2):
- Identifique as 5 operações atômicas mais frequentes
- Crie as micro-skills faltantes (uma por dia é um bom ritmo)
- Crie a constraint-skill de fronteiras arquiteturais
- Commite o
memory/MEMORY.mdcom as decisões já tomadas
No próximo mês (Fase 3):
- Crie as meta-skills para os workflows principais
- Conecte as skills em um grafo navegável
- Teste com sessão limpa — feature completa sem instrução de workflow
- Monitore as métricas: tokens por sessão, violações na PR review, tempo de feature
Para Continuar Aprendendo
A disciplina de context engineering está evoluindo rapidamente. Algumas referências:
- Anthropic — The Complete Guide to Building Skills for Claude: O guia oficial lançado em março/2026 pela Anthropic. Cobre progressive disclosure, estrutura de frontmatter, tipos de skill, boas práticas de description e quando usar
## Criticalvs CAPS. É a referência primária para autoria de skills no Claude Code. - Anthropic — Best Practices for Claude Code: Guia oficial sobre como estruturar contexto para agentes Claude
- Anthropic — Extend Claude with Skills: Documentação técnica sobre skills e como o Claude as usa
- Martin Fowler — Context Engineering for Coding Agents: Análise arquitetural da disciplina por um dos maiores nomes em engenharia de software
- HumanLayer — Writing a good CLAUDE.md: Guia prático com exemplos reais
- Agent Skills — Open Standard: Especificação aberta do formato de skills para agentes, com guia de autoria e exemplos
- Anthropic — Skills API Reference: Endpoint
/v1/skills, parâmetrocontainer.skillsna Messages API, e integração com o Claude Agent SDK — relevante para quem constrói pipelines automatizados ou quer usar skills programaticamente fora do Claude Code/Claude.ai
Este artigo foi escrito em março de 2026 como referência técnica para equipes que trabalham com múltiplos agentes de IA em projetos de software. Os princípios são independentes de stack — os exemplos usam Node.js + Express + React, mas se aplicam a qualquer tecnologia.
Apêndice: Templates Completos
Template: CLAUDE.md
# [Nome do Projeto] [Componente]
[Stack principal] + [Padrão arquitetural]. [Uma linha de contexto.]
## Arquitetura
- [Onde fica o código novo — camada/diretório]
- [Onde fica o código legado — se houver]
- [Onde fica o código compartilhado]
## Regras Críticas
- NUNCA [violação crítica 1]
- NUNCA [violação crítica 2]
- SEMPRE [obrigação crítica 1]
- SEMPRE [obrigação crítica 2]
- NUNCA [violação crítica 3]
## Comandos
- `[comando 1]` — [descrição breve]
- `[comando 2]` — [descrição breve]
- `[comando 3]` — [descrição breve]
- `[comando 4]` — [descrição breve]
## Skills
Ver AGENTS.md para lista completa de skills e guia de seleção.
## Memória
Ver `memory/MEMORY.md` para decisões arquiteturais e padrões confirmados.
Template: AGENTS.md
# AGENTS.md — [Nome do Projeto]
## Fonte de verdade
1. `CLAUDE.md` (contexto Claude Code)
2. `.github/copilot-instructions.md` (contexto Copilot)
3. `.github/skills/*/SKILL.md` (procedimentos sob demanda)
4. `docs/` (specs, requisitos, decisões)
## Skills disponíveis
**[Categoria 1]:**
- `/[skill-name]` — [descrição em uma linha]
- `/[skill-name]` — [descrição em uma linha]
**[Categoria 2]:**
- `/[skill-name]` — [descrição em uma linha]
## Regras operacionais
- [Regra 1 — imperativa]
- [Regra 2 — imperativa]
- [Regra 3 — imperativa]
## Memória do projeto
- `memory/MEMORY.md` — decisões arquiteturais, padrões confirmados, bugs conhecidos
- Ler no início de sessões que envolvam arquitetura ou módulos em migração
## Fallback
Se um arquivo referenciado não existir:
1. Reportar brevemente o bloqueio
2. Usar melhor alternativa disponível
3. Registrar suposições feitas
Template: Micro-skill
---
name: [verbo-substantivo]
description: [Gerúndio + o que faz + quando usar]. [Terceira pessoa, 1-2 frases.]
---
# Skill: [Nome Legível]
## Quando usar
- [Situação 1 em linguagem natural]
- [Situação 2 em linguagem natural]
- [Situação 3 em linguagem natural]
## Checklist
### 1. [Componente/arquivo principal]
- [ ] [Regra concreta e verificável]
- [ ] [Regra concreta e verificável]
- [ ] [Regra concreta e verificável]
### 2. [Segundo componente, se houver]
- [ ] [Regra concreta e verificável]
- [ ] [Regra concreta e verificável]
## Consulte também
- [[skill relacionada]](../ [skill-name]/SKILL.md)
Template: Meta-skill
---
name: [verbo-workflow]
description: [Gerúndio + o que compõe + quando usar]. [Meta-skill que orquestra X, Y, Z.]
---
# Skill: [Nome do Workflow] (Meta-Skill)
## Quando usar
- [Tipo de tarefa que ativa esta meta-skill]
- [Variação do tipo de tarefa]
## Inputs necessários
- [O que você precisa saber antes de começar]
- [Spec, endpoint, entidade envolvida]
## Workflow (execute nesta ordem)
### 1. [Primeira etapa]
→ **Usar skill: [[micro-skill-1]](../[micro-skill-1]/SKILL.md)**
- [Nota específica para esta etapa, se necessário]
### 2. [Segunda etapa]
→ **Usar skill: [[micro-skill-2]](../[micro-skill-2]/SKILL.md)**
### 3. Verificação final
→ **Usar skill: [[enforce-boundary]](../enforce-boundary/SKILL.md)**
```bash
[comando de validação final]
```
Template: Constraint-skill
---
name: enforce-boundary
description: Verificando fronteiras arquiteturais antes de finalizar qualquer mudança. Use como checklist
final em qualquer edição de código.
---
# Skill: Enforce Boundary
## Quando usar
- Antes de finalizar qualquer mudança em código backend
- Como checklist final de qualquer meta-skill
- Ao revisar código de outro desenvolvedor ou agente
## Regras de Fronteira (NUNCA violar)
- [Camada A]: NUNCA importe [Camada B] ou [Framework X]
- [Camada B]: PODE importar [Camada A], NUNCA [Infraestrutura]
- [Camada C]: PODE importar [ORM], [Framework HTTP]
## Checklist de Verificação
- [ ] [Verificação 1]: arquivos em [camada] importam apenas [permitidos]
- [ ] [Verificação 2]: sem imports de [proibido] fora de [contexto permitido]
- [ ] [Verificação 3]: [componente X] chama [Y], nunca [Z] diretamente
- [ ] [Verificação 4]: testes existem para [o que deve ser testado]
## Validação Automatizada
```bash
# Script determinístico — mais confiável que regras em linguagem natural
scripts/check-boundaries.sh
[comando de lint]
[comando de testes]
```
## Critical
- Validações programáticas (scripts) são preferíveis a instruções em linguagem natural para verificações
de fronteira. Código é determinístico; interpretação de linguagem não é.S
- Se o script retornar erro, o agente DEVE corrigir antes de prosseguir.